





1、码长定理
汉字按字源拆分属文字学内容,但拆分目的主要是为了便于计算机输入汉字,这又涉及到了计算机科学的内容,因此说汉字编码属于一种综合科学范畴,这是用数学研究汉字编码的基础。
汉字按不同方法拆分都能形成一种构件,下面定义构件:以某种规则确定的具有组配汉字功能的笔画结构之集合。在汉字拆分活动中,为了纠正不规则拆分给信息处理工作带来的不便,国家对汉字拆分进行了规范,目前汉字只能按字源关系拆分成基础部件(GF3001―1997),因此这种拆分属于文字学范畴。现在我们是用数学研究汉字拆分,建立汉字拆分数学模型,这就必须抛开汉字的文学内涵及图形结构,只考虑汉字、构件、笔画这三个最基本的要素,建立汉字拆分数学模型,用数学研究这三个基本要素之间的关系,这就是汉字的数学拆分,属于数学范畴。汉字数学拆分的最小单位是笔画,从整字到笔画,汉字每拆分一个笔画,都能形成一组新的构件与之相对应,因此构成一种函数关系,在这里,笔画是自变量用x表示,构件是因变量用字母y表示,因此y 是x的函数,可用公式y=∫(x)表示。
在汉字数学拆分中,把组成构件的个体称为字元,字元种类指构件中互不相同的字元,字元总数还包含所有重复的字元。对某一确定字符集,在能够形成的所有构件中,整字是最大构件,字元种类最多但总数最少,都等于字符集中汉字数量;笔画是最小构件,字元种类最少,基本笔形只有横竖撇点折五种,但总数最多,等于该字符集汉字数量乘以汉字平均笔画数;除此之外的所有构件,其字元种类和字元总数都在整字与笔画之间,码长定理定义如下:
对已确定的字符集及字符集中的任意构件,汉字平均码长等于汉字平均笔画数与字元平均笔画数之商。
码长定理是关于全息码的汉字编码定律,全息就是全部信息,全息码要求汉字编码不能添加或减少任何笔画。对某一确定字符集,设Q为汉字总数,B为汉字平均笔画数,对于该字符集中任意一种构件,设q为字元总数,b为字元平均笔画数,都有QB=qb,式中Q及B是常量;q及b是变量,设q/Q=λ为汉字平均码长,所以λ=B/b,该公式亦称作码长公式。
在码长公式λ=B/b中, B是常数,对于GB2312―80字符集,B值大约等于11.0画;对于GB13000.1字符集,B值大约等于10.1画,对于GB18030―2000和GB18030―2005字符集B值目前还没有统计数值;b是自变量,定义域为(1,B),码长定理对汉字、构件和笔画三者之间关系的描述,并不针对单个汉字,而是对整个字符集说的,因此,这里b是指在字符集中对于任意一种构件,包括重复字元在内的所有字元(字元总数)平均笔画数,本文为了简化数值统计,用构件中不重复字元(字元种类)平均笔画数b1近似代替b值,例如GB13000.1字符集汉字有560个不重复部件(字元),平均笔画数为4.5笔,即b1=4.5笔,为了简化计算,b=4.5笔。
图1为函数λ=B/b曲线,又称码长曲线,这是一反比曲线,曲线1对应GB2312―80字符集,曲线2对应GB13000.1字符集,将自变量b定义域(1、B)代入拉格朗日中值定理λ(B)-λ(1)=λ'(b)(B-1),可求出码长曲线中值点P(b,λ)值为
:λ= b=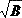 =
= =3.3;曲线2的λ=b==
=3.3;曲线2的λ=b== =3.2。
=3.2。
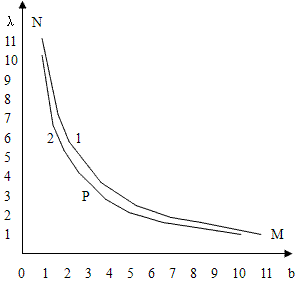
图 1
汉字数学拆分囊括了包含文字学拆分在内的全部汉字拆分方案,能从微观展开分析汉字拆分,从中找出汉字编码规律并用以指导汉字编码,为彻底解决目前汉字编码问题提供理论依据。
2、推论一
在汉字按字形编码中,无论目前已有的还是将来要产生的所有编码方案,如果存在着简单方便、适于普及的汉字编码,那么在码长曲线上这种编码必定趋于中值点。
在图1码长曲线M―P区间,因码长比较短,汉字输入功能突出,汉字排序功能具有局限性,目前汉字编码方案大都集中在这一区间,当λ趋于1时b趋于B,近似整字输入,字元没有脱离汉字形、笔画数多,汉字输入难度大,在该区间增加码长能有效降低汉字输入难度。
在码长曲线P―N区间,因码长比较长,汉字排序功能突出,汉字输入按键次数增多,冗余值比较大,当λ趋于B时b趋于1,近似笔画输入,有很多字母键闲置,汉字输入要频繁按键,当b=1时就是目前广泛用于汉字排序的笔画检字法,在该区间减少码长不但能提高汉字输入效率,还能使汉字排序功能由单笔画向多笔画结构转化。
在码长曲线中值点P附近,位于M―P和P―N区间交界处,汉字输入功能由整字沿着笔画减少方向趋近于极值点P;汉字排序功能由单笔画沿着增加笔画方向趋近于极值点P,因此在中值点P附近的汉字编码,具有汉字输入及排序双重功能,存在着简单方便、适于普及的汉字编码特征。
3、推论二
汉字按字源关系拆分成的基础部件,因基础部件在码长曲线上趋于整字,具有汉字特征,因此直接采用基础部件编码形成的所有汉字输入法,都具有“难学”这一特征,因此是不能普及的。
从推论一得知,简单方便、适于普及的汉字编码在码长曲线上必定趋于中值点,对于GB13000.1字符集,位于码长曲线中值点的构件字元平均笔画数b=3.2笔,而按字源拆分构成的560个部件(字元),平均笔画数b1=4.5笔,因此b=b1=4.5(实际笔画少的字元重复量要多些,也就是b1要稍大于b),所以部件的平均笔画数要多出1.3笔,由此可以断定,直接采用部件编码都具有“难学”这一特征,这是由汉字编码规律决定的,也能从三十年的汉字编码实践中得到验证。
 字形与拉丁字母相结合就应该能产生汉语拼形方案
=====你搞错了,汉字的形状与英文的形状怎么可以做一对一比较,简直是牵强附会的结果。
英汉只是借用26个符号,来表达各自的发音系统。不是26个符号与中文产生什么形状上的相似才使用它们的。
你的高见,可以用在学术上,用在实践上,估计很难推广的。汉字就是汉字,与英文字母很难在形态上相通的。
字形与拉丁字母相结合就应该能产生汉语拼形方案
=====你搞错了,汉字的形状与英文的形状怎么可以做一对一比较,简直是牵强附会的结果。
英汉只是借用26个符号,来表达各自的发音系统。不是26个符号与中文产生什么形状上的相似才使用它们的。
你的高见,可以用在学术上,用在实践上,估计很难推广的。汉字就是汉字,与英文字母很难在形态上相通的。
 很有发展前景
很有发展前景