





�������������ֵ������ṹ��Ω��������ġ��֡�
�������ʻ������ñ���Ϊ�����Եļ�¼����ʱ��ÿ�����ֶ���һ��һ�ʵ�д�����ģ����ǣ��ʻ������ǵ������ֵĻ����ṹ��λ����ֻ�ǵ������ֵ���д��λ��Ҳ����˵���ʻ��ǵ������ֵ���С�����ɵ�λ������ֻ�������������ּ������Լ�¼���ŷ�չ�ݱ����ʷ�����У����ʡ���Ϊ��������Ҫ��¼������һ�ض���ʷ���в����ʹ��ڵ�һ�����
��������˵������Ķ�����������εģ����Ľṹ�ͱʻ���û��һ��֮�棬���������屾��������������ͼ�θ��ӽ���ֱ��������֣��ʻ��Ŵ��Ĺۣ������γ�ƽֱ������������д�ıʻ�ϵͳ�ˣ����գ�147����
һ�����֣��ֽ�ʻ����ܲ����ٷֽ��أ���Ȼ�������ٷֽ��ˡ���ˣ��ʻ��ǵ��ֽṹ�ϵ���СԪ�ء�
���İѱʻ���Ϊ������
���壴�������������ñ���Ϊ�����Լ�¼������д���庺��ʱ��ÿһ�δ���ʵ�������ʱ����ʶ��ں����Լ�¼�����ϵ��˶��켣[14] ��
�����ǵ��������ֵ���С�ṹ��λ��
������ָ����������η���ָ�·�������ĺ����Լ�¼���š�
�������˵����֮��ʶ��Ҳ����춲��ܷ֡����ܷ�һ��Ϊ���֣���㻭�ز������������Ƕ������ӡ�����ͯ��ʱ������֪ijΪ���Σ�ijΪָ�£��������ּ��ϴ˶����Գ�֮�������ּ��ϴ������Գ�֮�����ִ�������֮�����������ޡ��� ����������·����
�������イ���Ǻ����ֵĽ�ѧ������Ҳ˵�������ַ����������Ĺ۵㣬����ĺ�����ֻ�������η���ָ�·�������ĺ����Լ�¼���ţ�����Ϊ����Ӧ��ᷢչ�����������Ա������Ҫ�����������е���һ����ŵĻ������û��ⷨ�����������·��ţ��磺�ϡ�С���¡���Ϊ���⡱�����������á�Ϊ��ث���ȵȡ����������ǵ�������ӷḻ��Ҫ���и���ķ�������¼�������ⷨ�������ˣ����������������磺���㡱ԭ���������֣���ֻ��������ܳơ����ŶԿ�������ʶ�IJ������Ϊ���ܹ�ȷ�ر�����ͬ������㣬���������ˡ�����������������������Ⱥ͡��㡱��ϣ�����ˡ��𡱡����㡱�����𡱡�����һ����������
�����������ɡ��⡱�ġ�С���͡������ɡ�ث���ġ���������Ů���͡��ӡ������Ƕ���ĺ����Լ�¼�����ˡ����˰��������������η���ָ�·�������ĺ����Լ�¼���ų�Ϊ��������
�����ɡ��ġ������⡢�����ȷ���������ĺ���ĺ����Լ�¼���ų�Ϊ���֡���
����������Ԫ
��������������Ԫ
ͨ��4�����ڵ����ۿ�֪�����ġ��ǽ��ڡ��֡��롰����֮���һ���м����ϵĹ��ֵ�λ�����ǡ��ġ������ǹ��ɵ��ֵĻ�����λ����ǰ���ᵽ���ġ�ث���֣����á������͡��á�������ɵĻ����֡���ɡ�ث���Ļ�����λ�ǡ��������ģ��͡��á����֣��������ǡ���������Ů�������ӡ��������ġ����ѡ�ث���ַ���Ϊ�ɡ���������Ů�������ӡ���ɣ���������������ֹ��ɵ���ʵ��������������Ҳ˵��ͨ��
Ϊ�˽�����ɺ��ֵĻ�����λ��һ���⣬�������롰��Ԫ����һ���
���壴���������빹��һ�����֣��ڸ������������������ã��ұ����������������ڡ���ȷ�����壬�ṹ��ģС���ҽ�С�������빹��ĵ��ֵĺ����Լ�¼���ţ�����������ֵ���Ԫ��
���еĺ��֣���������Ԫ���ɵġ����ں�������˵��ÿ�������������������ṹ��λ��ɣ���Щ�ṹ��λ������Ԫ�������ģ������֣���˵�����ǿ������������ɵ�����Ԫ��ɵ��֣������Ԫ��������ģ������֣�������
���빹�ֵ���Ԫ�����������빹��ĵ����У�������һ�������õġ������ڸõ����л����������塣�硰�����֣����еġ�ܳ�����塢������������ǰ���ᵽ���ġ�ث���֣����еġ������͡��á���������ʾ�����á�����˼�����DZ���ġ�
��ܳ�����������������������á��ȶ��������������ڣ���ܳ�������H������c��o������ȷ������[15] ��
Ӧ��˵�����ǣ����顱�͡�![]() ���Լ���Ů���͡��ӡ�Ҳ�������������ں���ȷ�����壨���顱�ǡ��ˡ��ı��Σ�������Ϊ���к͡��ˡ���ͬ�����������塣��
���Լ���Ů���͡��ӡ�Ҳ�������������ں���ȷ�����壨���顱�ǡ��ˡ��ı��Σ�������Ϊ���к͡��ˡ���ͬ�����������塣��![]() ����huà�����仯�� �壩�������Dz��ǡ�������ث���Ļ������ɵ�λ�����顱�͡�
����huà�����仯�� �壩�������Dz��ǡ�������ث���Ļ������ɵ�λ�����顱�͡�![]() ���Ľṹ��ģ�ȡ�����С����Ů���͡��ӡ��Ľṹ��ģ�ȡ��á�С�����Ƕ���������Ԫ�����С��ṹ��ģС���ҽ�С������빹��ĵ��֡���һ���������顱�͡�
���Ľṹ��ģ�ȡ�����С����Ů���͡��ӡ��Ľṹ��ģ�ȡ��á�С�����Ƕ���������Ԫ�����С��ṹ��ģС���ҽ�С������빹��ĵ��֡���һ���������顱�͡�![]() ���ǡ���������Ԫ�������ǡ���������Ԫ��ͬ������Ů���͡��ӡ��ǡ��á�����Ԫ�������ǡ�ث������Ԫ��
���ǡ���������Ԫ�������ǡ���������Ԫ��ͬ������Ů���͡��ӡ��ǡ��á�����Ԫ�������ǡ�ث������Ԫ��
������������������ث�����ֵ����ӣ��ں������Ǿٲ�ʤ�ٵġ����ں������������ֺͻ����ֶ��ߺ�����ռ������������95�����ϣ��������ֺͻ����־��ɶ�����������ϵ���Ԫ���ɣ��������Ϸ��������Dz�ʧһ���Եġ�
��������������Ԫ���롰�ġ���ԭʼ��Ԫ
��Ԫ������ͬ�ڶ���ġ��ġ������ڶԡ������͡�ث�����ֵķ������Ѿ��õ���˵�����������ʣ����еġ��ġ������Dz��빹�캺�ּ���Ԫ�أ�Ҳ������Ԫ����������ÿһ���ֶ��ԡ��ġ�Ϊ������λ���ɡ�������ѧ�ϵ�������˵������һ��������������DZ�Ҫ������
���ġ���������Ԫ�����Ծ�����أ����Ǿ��зdz�ǿ�Ĺ���������
���壴�����������������η���ָ�·�����ļ�¼�����ݱ�����Ķ���ġ��ġ�����Ϊԭʼ��Ԫ��
���ں����ֳ����ݱ�Ľ����һЩԭ������ġ��ġ�����˺���ġ��֡���һЩԭ������ġ��֡�����˶���ġ��ġ������硰�����֣�ԭΪ�����Σ����ڿ��Էֽ�Ϊ���ڡ��硱���������֣�СΪ�������Σ����ڿ��Էֽ�Ϊ���ڡ��ڡ������硰���������Ĵӡ��֡����ӡ��ˡ�����ʾ����������˼�����⡣���顱�֣�С�ӡ����������ߡ�����Ϊ�����֣����ڡ������顱���Ƕ����֡����������1991��P316������ǰ�潲�ġ�ԭʼ��Ԫ������������һ�������ڡ�
������������������Ԫ������Ԫ
���壴���������빹�ֵĶ���ġ��ġ�����Ϊ������Ԫ��
������Ԫ���Ρ����������Dz��ɷֽ�����塣
���壴���������빹�ֵĺ����ֳ�Ϊ������Ԫ��
���壴��������Ԫ������������õ���Ԫ��Ϊ��Ԫ��
���壴��������Ԫ������������õ���Ԫ��Ϊ��Ԫ��
���ĸ�����ĺ����������Ͳ�һһ����˵���ˡ�
Ϊ�˱������ۣ������ڹ����ϰ�ÿ�����ֱ���Ҳ������Ԫ��������ѧ�ϰ�һ����������������Լ��һ����
4��2��4����Ԫ֮�����Ե��ϵ����Ԫ�ִ�
���빹��ͬһ�����ֵ�������Ԫ֮���������Ե��ϵ�����ԡ�������Ϊ���������Ѿ�֪�������������ɡ�ܳ���͡��������ɣ����������ɡ���͡�![]() �����ɡ���Ȼ����ܳ���͡������IJ����ڡ�����֮ǰ�������顱�͡�
�����ɡ���Ȼ����ܳ���͡������IJ����ڡ�����֮ǰ�������顱�͡�![]() ���IJ������ڡ�����֮ǰ�����ǿ�������˵�����顱�͡�
���IJ������ڡ�����֮ǰ�����ǿ�������˵�����顱�͡�![]() ���Ľ�ϲ����ˡ���������ʱ���顱����Ԫ����
���Ľ�ϲ����ˡ���������ʱ���顱����Ԫ����![]() ��Ϊ��Ԫ����Ԫ��������ܳ���롰�����Ľ���ֲ����ˡ���������ʱ��ܳ������Ԫ������������Ԫ��������Ѻ������˸��Ϳ���˵�����顱�͡�
��Ϊ��Ԫ����Ԫ��������ܳ���롰�����Ľ���ֲ����ˡ���������ʱ��ܳ������Ԫ������������Ԫ��������Ѻ������˸��Ϳ���˵�����顱�͡�![]() ���ǡ������ĸ�ĸ������ܳ���͡��������ǡ������ĸ�ĸ������һ��������������Ԫ���塣����ѡ��顱�͡�
���ǡ������ĸ�ĸ������ܳ���͡��������ǡ������ĸ�ĸ������һ��������������Ԫ���塣����ѡ��顱�͡�![]() ����Ϊ��������ô�����������ӱ����������������ﱲ������ӡ���������������Ѱ�棬��ô��ܳ���͡������ǡ������ĸ�ĸ�������顱�͡�
����Ϊ��������ô�����������ӱ����������������ﱲ������ӡ���������������Ѱ�棬��ô��ܳ���͡������ǡ������ĸ�ĸ�������顱�͡�![]() ���ǡ��������游ĸ��
���ǡ��������游ĸ��
���İѵ�ǰ��Ҫ��������д�����룩�ĵ��ֳ�Ϊ������Ԫ������Ϊ���ɵ�����Ԫ�Ļ�����λ����Ԫ��Ϊ�õ��ֵ�������Ԫ������Ϊ���ɸ�����Ԫ�Ļ�����λ����Ԫ��Ϊ�õ��ֵ������Ԫ��
�����������ۣ����ǰѶ��壴��������Ϊ���壴������
���壴��������Ԫ�����������������κ����ڣ�������ȷ������ĺ����Լ�¼���š�
����
���壴������������Ԫ������ǰ�账�����������д���ĵ��������Լ�¼���š�
���壴��10��������Ԫ�������빹��һ��������Ԫ���������������������ã��ṹ��ģС���ҽ�С�ڸõ�����Ԫ����Ԫ��
���壴��11�������Ԫ�������빹��һ��������Ԫ���������������������ã��ṹ��ģС���ҽ�С�ڸø�����Ԫ����Ԫ��
������������ԭ����Ԫ�ͱ�����Ԫ
�������е���Ԫ��������һԪ���ε�������硰�ˡ���Ϊ�����������Ԫ��������һ����Ԫ���ʱ����������Ϊ���顱�����֡���Ϊ�����������Ԫ��������һ����Ԫ���ʱ����������Ϊ���С�����������Ϊ�����������Ԫ��������һ����Ԫ���ұ�ʱ����������Ϊ���֡���ƽ�����ϰ�߰ѡ��顱�����С������֡�����Ԫ��Ϊ�����ס��������ס���������������ࡶ˵�Ľ��֡�ʱΪ�Ѻ�����ͬ��Ԫ���ֽ��й����Ա��ڼ�����������ġ�������Ϊ������ַ�����Ϣʱ�����ص㣬������һԪ����������Ϊ�á�
��Ԫ��һԪ���Σ���1956�깫����1986�����¹������ġ������ܱ�����1965�깫���ġ�ӡˢͨ�ú������α�����Ҳ����ȷ�Ĺ涨��
�������ܱ����涨����һ����350�����ֲ�������ƫ���á�Ҳ����˵����Щ��Ԫ��������Ԫ�����֣���ʱ��Ҫ�ü����Σ���Ϊ������Ԫ�������Ԫ��ʱ�����÷������Ρ�
�������ܱ����ڶ����й涨ʮ�ĸ�����Ԫ��ƫ�ԣ����������������Ԫ��ƫ�ԣ���ʱ��������Լ��硰�ԡ�Ҫ�á�ڥ��������Ҫ�á��ġ��ȵȡ�����Ϊ������Ԫ�����֣���ʱ������
�����硶ӡˢͨ�ú������α����涨�������������������������������������ӡ�����ֹ������ţ�������㡱���������������������㡱����Ѫ����ԭʼ��Ԫ��Ϊ������Ԫ��ƫ�ԣ������ֵ����ʱ��ĩ�ʵĺ������Ϊ�ᣬ�硰�ء��������������ߡ�������������������硱���������·���������������桱�����ʡ������ơ��ȡ����֡��������������롱��������Ϊ������Ԫ��ƫ�ԣ������ֵ����ʱ��ĩ�ʵ���������ΪƲ���硰�ݡ��������������ѡ������硱�ȡ����¡������̡������ס������硱�����桱����Ϊ������Ԫ�����ֵ����ʱ��ĩ�ʵ������Ϊ�㣬�硰�䡱�����ޡ����������������������塱�ȡ������������ȡ������⡱�����ߡ�����Ϊ��Ԫ�����´���Ԫ�����ʱ��ĩ�ʶ�����Ϊ���ᡣ�硰�ġ������ޡ������ԡ������С��ȵȡ�
�ڡ��»��ֵ䡷�͡�������ֵ䡷�У����ѡ�צ���͡�������Ϊͬһ�����ѡ�Ȯ���͡��롱��Ϊͬһ���ȵȣ�Ҳ˵���ˡ������ǡ�צ���ı��Σ����롱�ǡ�Ȯ���ı��Ρ�
���壴��12��һԪ���ε���Ԫ������Ϊ������Ԫʹ��ʱ�ļ�����״Ϊ�����Ԫ��ԭ�Ρ�ʹ��ԭ�ε���Ԫ��Ϊԭ����Ԫ������Ϊ������Ԫ�������Ԫʹ��ʱ��ԭ������ļ�����״Ϊ�����Ԫ�����Σ�ʹ�ñ��ε���Ԫ��Ϊ������Ԫ��
������Ԫ��Я������������Ϣ�����Ӧ��ԭ����Ԫ��ͬ�������ڡ�˵�Ľ��֡��а��ԡ��С�Ϊ������Ԫ���־���Ϊ�����֡������ԡ��롱Ϊ������Ԫ���־���Ϊ����Ȯ���ȵȣ�����֤����
������������ʡ����Ԫ
�������飬��ijЩ�ֶ��С�ijʡ�Ρ�����ijʡ�����ķ�������ʡ�Ρ���ָʡ��ij���ֵ��Σ��壩Ԫ��ʡ����ָʡ��ij���ֵ���Ԫ�����硶˵�ġ��ԡ��ء��ֵķ����ǡ��Ӻ̣���ʡ������ָ���l��Ϊ��������ʡ����Ԫ�������M��Ի��������Ϊ�أ�������Ҳ����˵�����l����Ȼֻ�ǡ������ľֲ������ڡ��ء�������Ȼ����������������Ϣ�����á�Ӧ��˵��������ˡ��Ρ���һ���أ��ڡ����������塱�����桰�l������ͬ�ڡ��������֣����c����ruí�����ֱ�����Ϊ���������gʡ�����������ǡ�ʡ�Ρ����ǡ�ʡ������������������ʡ���˲�����Ԫ��
��������13����Ϊ������Ԫ�������Ԫʹ��ʱ��ʡ���˲����ϴ���Ԫ����Ԫ��Ϊʡ����Ԫ����Ӧ��ʡ��ǰ����Ԫ������ʡ����Ԫ��ԭ����Ԫ��
ʡ����Ԫ��Я����ԭ����Ԫ����������Ϣ���빹�ֵģ����ԣ�����ԭ����Ԫ�ĵȼ���Ԫ��ʡ����ԪЯ������������Ϣ�������Ӧ��ԭ����Ԫ��ͬ��
����ʡ����Ԫ��֮ԭ����Ԫȱʡ�˲����ϴ���Ԫ�����������������Ԫ�������ϵ�ģ���ԣ��������ϵ�ģ���ִ�����������Ԫ�������ϵ�ģ���ԡ�
ʡ����Ԫͬ������Ԫ������������ԭ����Ԫ���ڲ��졣���ߵ������ǣ�ʡ����Ԫʡ�Ե��������������ϴ���Ԫ������ʡ�Բ�����Ԫ�Ժ����²��ֵļ�����״��ԭ����Ԫ����Ӧ���ֵļ�����״��Ȼ��ͬ��������Ԫ�ı�������ص���״�����κ��ڲ���һ��������������ȫ�����صļ�����״��ԭ����Ԫ��ͬ����Щ������Ԫ����������Ҳ����ԭ����Ԫ��������������ȡ�
������������������Ԫ
�����ּ����д���һ���Ӽ����������ּ��������ּ��е�Ԫ���ڲ�ͬ�����Ի�������ʱȡ��ͬ�Ķ��������Ƶأ������ּ��е�Ԫ����Ϊ�����������Ԫ���빹����һ����Ԫʱ���ڲ�ͬ�Ĺ��ֻ�������ȡ�Ķ�����ʱҲ����ͬ��
�硰�䡱����������jù ��g��u���ڡ��������������������������У�������g��u����Ϊ��Ԫ���빹�ֵģ����ڡ��С����У�������jù ����Ϊ��Ԫ���빹�ֵġ����硰ꧡ���Ҳ������������һ��ji��n��������һ����cán�����ڡ��㡱����dz����������������Ԫ��������ʱ���õ���ji��n�������ڡ��С�����ջ����������������Ԫ��������ʱ���õ���cán����
���壴��14���Ը�����Ԫ�������Ԫ���ݳ��ֵĶ����֣���Ϊ������Ԫ��
������������������Ԫ
ijЩ���ֵ��ϴ���Ԫ֮�����һ��������������ع�������ν�����ع��á�����ָ������Ԫ��Ϲ���һ����һ����Ԫʱ�����ڽ�ϲ��������صļ�����״��ͬ����ʡȥ����һ����Ԫ���ⲿ�����أ�����ijЩ���ء����硰�����֣�����ʡȥ�ˡ���ͷ�ϵġ��ˡ����á������͡��𡱹����ˡ����������±߲��ֵ����ء���˵�ġ�����������ӽ𣬸���������������ֵ䡷������4177ҳ��![]() ��������ͬ���������������ע��������������������ǰ���һ����Ԫ��Ϊ��������Ԫ��[16] ��
��������ͬ���������������ע��������������������ǰ���һ����Ԫ��Ϊ��������Ԫ��[16] ��
���壴��15�����������Ԫ��ͬ���빹��һ����һ����Ԫʱ��������˫��ʡ����������һ��Ԫ���ڴ������أ���Է��������뼺��ϲ������أ������������Ԫ��Ϊ������Ԫ��
��������������������Ԫ��ļ���λ�ù�ϵ
ǰ���ᵽ�������빹��һ���ֵ�������Ԫ���һ����Ԫ���塣�������Ԫ�����У�������Ԫ֮�����ѪԵ��ϵ�������������ֹ�ϵ��һ����Ԫ֮����������ϵ��������Ԫ֮��ļ���λ�ù�ϵ��
��Ԫ����������ϵ���ڣ������������ͣ�����������С�����в�������������������Ԫ֮��ļ���λ�ù�ϵ��
һ��������Ԫ���丸����Ԫ֮��ļ���λ�ù�ϵ���������֣������ǡ����ҹ�ϵ���������¹�ϵ������������ϵ��[17] ������Χ��ϵ���͡������ϵ����
����Сѧ��ʶ�ֽ�ѧ�У�ϰ���ϻ����������ҹ�ϵ�����������¹�ϵ������ʵ�������Ԫ����Ρ��������ϵ��ѪԵ��ϵ���������������ֹ�ϵʵ�ʲ������ڡ��������ʵ�����Ƿ����ڡ����¹�ϵ���������ҹ�ϵ���͡������ϵ���ġ�
���硰������������Ӽ�����״�Ϸ��������Խ��������������¡���һ�������γ������ҹ�ϵ�����������������������Ȼ�������ɡ��͡�������������Ԫ���ɣ����С�������Ԫ���������壨�Σ�Ԫ������������Ԫ�������ҹ�ϵ��
���硰�ܡ������ɡ�嵡��͡�ɽ������������Ԫ�������¹�ϵ����˵�ġ������ܣ�ɽ�����ߡ���ɽ��������������ע�����ܣ���νɽ����Ϊ�����ֶ�������ӡ�������ѡ��ܡ�����Ԫ�ṹ��ϵ����Ϊ���ɡ�岡������ء�����ɽ�����ɵġ������¹�ϵ������Ȼ����
������Ԫ��Ĵ����ϵ��ƽʱ���ǽ��ý��٣���ʵ��һ���ֻ��Dz��ٵġ��硰�ԡ������ɡ��¡��͡��С�����������Ԫ���ɴ����ϵ����˵�ġ������ԣ������£������������С��֡��ɡ��С��͡��硱���ɴ����ϵ����˵�ġ������֣���ͨ��Ҳ�����У������������硰�����������������á������Ρ��ȵȶ�������������Ԫ���ɴ����ϵ���֡�
���ڰ�Χ��ϵ����ʶ�ֽ�ѧ��ϰ���ٰ���ϸ��Ϊ��ȫ��Χ���͡����Χ�������С����Χ���ַ�Ϊ�����°�Χ���������Ұ�Χ���������°�Χ���������ϰ�Χ���� �ȵȡ������Ρ����������ۺϷ�������ȫ��Χ���͡����Χ������ȴ����ͬ�����硰�����͡�ϻ��������һ��������Ԫ��Χ��һ��������Ԫ���������ǡ�����wéi������Χ������ϻ���ǡ��Σ�f��n������Χ���ס������С������ǡ��ȣ�y��n������Χ�����������족�ǡ��㡱��Χ���ȵȡ����İ�����ͳ��Ϊ����Χ��ϵ��������ϸ�֡�
��Ԫ��ļ���λ�ù�ϵ����Ԫ����������ϵ�����ܲ��ɷֵ���ϵ��һ��أ���һ��������Ԫ�ļ��νṹ�з��������ļ������֣����Ǹõ�����Ԫ�ĸ�����Ԫ�����ҹ�ϵ�е����������֣����¹�ϵ�е����������֣���Χ��ϵ�еİ�Χ���ֺͱ���Χ���֣������ϵ�еı����岿�ֺʹ��岿�֣�������ϵ���γɶ����������֣�������ˡ����ݸ���Ԫ�������е���������Ϣ������������ϵļ��νṹ������Ѹ��ȷ�ط���������Ԫ����һ����Ԫ����
����������Ԫ��
��������������Ԫ��
ͨ�������½ڵ����ۣ����ǿ��Եó����ۣ���ÿһ�������о����Էֽ��������Ԫ������Ԫ�������Ԫ�����������Ԫ���е���������ͬ�ã��е���������ͬ�ã����������硰�������Ĵ�ͬ�á����ڶ�����ļ�������Ԫ��˵��ֻ��һ����������Ԫ��
��ˣ����ǿ���˵��ÿһ�����ֶ������������Ԫ��ɵġ����ij���ֵĸ���������Ԫ����һ����Ԫ����ÿһ����Ԫ���ĸ������ǵ�ǰ��������д�����룩�֣���������Ԫ��������һ��ڵ㣬�ǵ�����Ԫ�ĸ�����Ԫ��������Ԫ����һ��ڵ���������Ԫ��
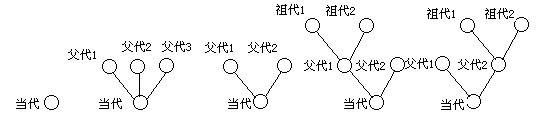
( a ) (b1) (b2) (c1) (c2)
ͼ�塡��Ԫ���ṹ����
��Ԫ���������������֣���ͼ�壩��һ����ֻ��һ�������������ڵ����Ԫ������������ԭʼ��Ԫ����������ģ��Ľṹ���ڶ����Ǿ��и����������ڵ���丸�ڵ����Ԫ��������(b1)�����˶�����ϵ����Ԫ�ṹ����b2��������ֻ���������ڵ�Ľṹ���پ��Ǿ��и����������ڵ㡢���ڵ��Լ���ڵ����Ԫ����Ҳ�����������һ����(c1)�������ģ��������ڵ���������ڵ㣬�������ڵ�û����ڵ㣻��һ����(c2)�������ģ��������ڵ�û�����㣬�������ڵ����������㡣���м��������Ԫ������һ�������ڵ�ͣ������ڵ㹹�ɣ��硰![]() ����
����
������Ԫ�����Էֱ��á��ڡ����������������������ˡ���������Ϊ����˵������ͼ������
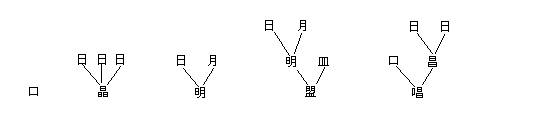
ͼ������Ԫ����
4������������Ԫ�����湹����
��Ԫ����һ���湹������������������Ȼ������Ҫ������
��Ȼ���ڿռ��ϣ��������£���Ҷ���ϣ���ʱ���ϣ�����������������Ҷ��
��Ԫ���ڿռ����Ǻ���Ȼ����ͬ�ģ��������£���Ҷ�����һ����Ԫ�����ϣ�����ʱ����ȴ����Ȼ�����棬��������Ҷ���������������ʳ���Ϊ���湹��������Ӧ�ģ��������ڱ�������жԺ����ֽ��з�������ȡ��Ԫʱ����Ӧ��ȡ����Ԫ���γ�ʱ������Ĵ��Ӹ��ڵ������Ȼ���м�ڵ㣬�����Ҷ��
4������������Ԫ���ǹ淶�����ֱ���Ľṹģ�͡�
����ÿһ�������֣�ֻҪ����������Ԫ���ṹ����ȷ������Ԫ���ϸ��ڵ㣨��Ԫ�������أ�������ӳ���ϵ��ͨ���Ը���Ԫ���ı���[18] �����ɵõ���������ֵı��롣
����ݣ�����������ͼ���е���Ԫ��������������Ԫ����ͨ����������ĸ�����أ���������ôͨ��������Ԫ��[19] ���ɵá��ڡ��Ĵ���Ϊ��k�����������Ĵ���Ϊ��jrrr�����������Ĵ���Ϊ��mry�������ˡ��Ĵ���Ϊ��mmmry�����������Ĵ���Ϊ��ckcrr����
�ɱ�����Ԫ�����õ��Ĵ����Ƿ��Ϻ����ֹ淶�ġ�
���ȣ�������Ԫ�����õ�����Ԫ�������д����Ƿ��Ϻ��������ι淶�ģ�������Ϊ��Ԫ����ӳ���������Ӧ�����ֵĹ淶���νṹ�����ԣ�������Ԫ���õ���Ԫ��Ϻ��������أ�������ӳ��õ��Ĵ�������Ҳ�Ƿ��Ϻ��������ι淶�ġ�
��Σ�������Ԫ�����õ��Ĵ��룬�Ƿ��Ϻ����ֶ����淶�ģ�������Ϊ�������أ�������ӳ�ľ��ǹ��ɵ��ֵĸ�����Ԫ�Ķ�����Ϣ�����е����뷴ӳ�ļ��Ǹõ��ֱ����Ķ�����Ϣ��
�ٴΣ�������Ԫ�����õ��Ĵ��룬�Ƿ��Ϻ�������д�淶�ģ�������Ϊ�������ڵ���������Ϣ�Ķ�ʧ����ǰ��˵������Ԫ������֮��һ��һ��ӳ���ϵҪ��������Ҫ���ṩ��������С�볤ֵͬʱ�ֲ���������볤ֵ����Ϣ��λ����Ԫ���������һ�����������ṩ�ı�����Ϣ��λ����Ԫ���������涨������볤���Ͳ����˱�����Ϣ���ࡣ�������Ķ���������������У�������ȡ��������ı�����Ϣ����Ԫ���ķ����������볤��һ�£�����Ʊ���ɵ���������Ϣ�Ķ�ʧ���硰�������ֽ�Ϊ����(��nè)���ڡ��ڡ��ڡ�ɽ���岿�ֺ�������볤��Ϊ������ֻ��ȡ���ڡ��ڡ��ڡ�ɽ����Ϊ��Ԫ��������һ�����ڡ����Ӻ����ֵ�ʹ�ù淶���������Dz������ģ�����ͬ�����ñ�д�ֲ����ٱ�ȱ��һ����������Ԫ���õ��Ĵ��룬������ֵ���������Ϣ�Ķ�ʧ������Ԫ�������ȡ�õ�һ��������Ԫ����Ѿ������˸õ��ֵ�ȫ��������Ϣ�������丸����Ԫ�У����Ѱ����������Ԫ��ȫ��������Ϣ��
�ɱ�����Ԫ�����õ��Ĵ���Ҳ�Ǿ߱�ʵ�û����ġ����ڴ����е�����ȡ����Ԫ�Ķ�����Ϣ������ֱ��ʹ�ü���������ϵ�26��������ĸ���������ʾ���أ����ؼ����������ȣ�ʡȥ�˶�����Ԫ��λ�ֲ��ļ��䣬��ѧϰ����ƴ����ʮ�ֽӽ����������Ĺ淶�ԣ��ͺ�����ʵ������Сѧʶ�ֽ�ѧ���ںϡ�
��Ԫ��ģ�ͻ��п��������ֿ⺺�ִ��������ϵõ�Ӧ�á��������룬�����ڼ�����д洢���ٸ�ԭʼ��Ԫ��������Ϣ������ʾ���ӡ���ʱ����������Ԫ���Ĵ���������������ɵ�����Ԫ�ĸ���ԭʼ��Ԫ�����Σ�������ص��㷨װ����֡��⽫����ؽ�Լ�������Դ��
�����Ԫ��ģ�ͻ������ڰ������������ڵ����к����֡���������Ҽ����ּ����е���һ����������������������֤��һ�㣬����Ͳ����ˡ�
4������Ӧ����Ԫ������ģ���д������ì��
4���������������ּ����������Ե�����Ϣ����Ҫ���벿�ֺ����ֱ�����Ϣ��ȱ��ì��
ǰ���ᵽ�������ֺͼ������������ĸ�����������ϵ�ì�ܣ�Ҫ�����DZ���Ժ�����ʵʩ���롣����֮�����ܽ����һì�ܣ�����Ϊ��26��������ĸ�����ÿ��ȡһ������Ԫ�ؽ���������ϣ��Ϳ��Բ���������������Ҫ��ı���ռ䡣��Ͳ�����һ����С�볤��Ҫ��������Ȼ�������Ԫ����Ϊ�ͣ����ؼ����������ȣ��볤Ϊ�����ռ��СΪ�ˣ����ɣ����������ڣ�����ʽ��![]() ���С�
����
![]() ������������������
������������������
�ԶԱ���ռ�Ҫ����С�ġ���������Ϊ����![]() ��
��![]() �������
�������![]()
![]() ������Ҳ����˵��ÿ���������������ṩ��ƽ����Ԫ��Ӧ�����ڣ���ʵ���ϣ����ں������ڱ���ռ�ķǾ��ȷֲ���Ҫ��ÿ�������������ṩ��ƽ����Ԫ����Ҫ���ڣ������ǣ���4���������ڵ�ͼ���У�������ֻ��һ����������Ԫ��������ʾ�˺����ּ����е��ֵĵ�����Ԫ�ṹ��Ҳ����˵��������Ԫ�����������Ϊ������Ԫʱ�����ṩ������Ҫ�����Ϣ������Ͳ���������Ե�����Ϣ����Ҫ���뵥����Ԫ������Ϣ��ȱ��ì����
������Ҳ����˵��ÿ���������������ṩ��ƽ����Ԫ��Ӧ�����ڣ���ʵ���ϣ����ں������ڱ���ռ�ķǾ��ȷֲ���Ҫ��ÿ�������������ṩ��ƽ����Ԫ����Ҫ���ڣ������ǣ���4���������ڵ�ͼ���У�������ֻ��һ����������Ԫ��������ʾ�˺����ּ����е��ֵĵ�����Ԫ�ṹ��Ҳ����˵��������Ԫ�����������Ϊ������Ԫʱ�����ṩ������Ҫ�����Ϣ������Ͳ���������Ե�����Ϣ����Ҫ���뵥����Ԫ������Ϣ��ȱ��ì����
����Ե�����Ϣ����Ҫ���뵥����Ԫ������Ϣ��ȱì�ܴ��ڵ�ԭ�����ڵ�����Ԫ�����Ρ�������IJ��ɷ��ԡ��������������£��Ե�����Ԫǿ�н��зֽ⣬���Ʊ���ɶ�����ֵ�֫�⣬�ƻ������ֵĹ淶ʹ�á�
4����������������Ϣ������Ҫ���벿����Ԫ�Ρ���������Ϣģ����ì��
��ͨ������Ԫ���ı������б���ʱ����Ԫ���ĸ����ڵ�ͳ䵱����Ԫ�Ľ�ɫ��Ϊ���ܷ����ʵ�ִ���Ԫ�����ص�ӳ�䣬��Ҫ��ÿ����Ԫ�ܹ��ṩ�����Ķ�����Ϣ����Ԫ���ĸ����ڵ���ǵ��ֵĸ�����Ԫ������ÿ����Ԫ��Ӧ�������Ķ�����Ϣ����Ԫ�ġ������������䡰�Ρ����صģ��ʶ���Ҫ��ÿ����ԪӦ�������ġ��Ρ������Ρ��������������֣����Ρ��������������塱������
�ڵ���ͨ�еĺ������У�ȴ�ִ����Ų�����Ԫ�Ρ���������Ϣģ���������һ����Щ���еĸ����������Ԫ��ԭ���ǵ��֣������ڲ����������ˣ����ǽ�����������ԭ�ȵĶ������硰�С��ֵ�����������Ԫ���ܣ�Chì�����͡�ء(Chù)�����������ֵĸ�����Ԫ֮һ���裨bao���������ǡ��ĸ�����Ԫ֮һ���h��b���������������ĸ�����Ԫ֮һ���ڣ�nè�����ȵȣ�����ǰ���ᵽ���硰�l��֮���ʡ����Ԫ�������䡰�Ρ���ʡ�ԣ�ʹ�������صġ���������ϢҲ���ģ���ˣ�����������Ԫ��ճ����һ��Ķ�����Ԫ֮�����ģ�������DZ�����Ԫ�Ķ�������ȷ�������ں��ּ�ʱ����ijЩ�ֵļ�ģ����������ʧ������Ԫԭ�еĶ�����Ϣ���硰�����ּ�Ϊ��Ӧ�����㡱����Χ�ġ���(su��)���͡��ġ�[20] �ɶ����ӿ�֤�ġ�![]() �����棬��ʧ����Ԫԭ�еĶ�����Ϣ��
�����棬��ʧ����Ԫԭ�еĶ�����Ϣ��
������������Ĵ��ڣ��������������Ԫ��Ϣ������Ҫ���뺺���ֵIJ�����Ԫ�Ρ���������Ϣģ����ì������һì�ܵĴ��ڣ�����˶�һ�����ֽ�����Ԫ�����ʹ���Ԫ����ȡ������Ϣ�����ѣ������ڱ���淶�Ժ�ʵ���Ե�ʵ�֡�
����������������Ψһ��Ҫ�������ռ��ͻ��ì��
һ�����뼯���е�ÿһ��Ԫ�أ���ÿһ�����룬�ں����ּ����ж�Ӧ�����ҽ���һ��Ԫ�ؼ�һ����������֮���Ӧ�������ijһ�����룬����ж�����������Ϻ�������֮���Ӧ����ô�������ڼ����������������ʱ���ֿ��д������ͻ�Ķ�����������Ϻ����־ͻ�ͬʱ��Ӧ�������ɻ��ҡ���Ȼ���������������ϲ���ѡ�������ķ�������һ������д������������Խ��������ٶ���Ϊ���۵ģ�ֻ����һ��Ȩ��֮�ơ����۴����ۻ��Ǵ�ʵ�õĽǶȿ��ǣ������ͻ������Ҫ�����ġ�
���ǣ�����ʵ�ü�ֵ���͵���ˮ�룬�������͵���һ�ֺ����ֱ���Ŀǰ��������������ͻ����Ϊ���ӣ������������조�ء������顱���ֵı��롣��������Ԫ���ķ������ɵó����ء��ɡ��ߡ��͡�Ҳ������������Ԫ���ɣ����顱�ɡ��С��͡��ɡ�����������Ԫ���ɡ������־�û�������Ԫ�����ߡ��ǡ�ˮ���ı�����Ԫ������������к͡�ˮ����ͬ�������壬����ȡ�������shui��������ĸ��s����Ϊ���أ����С��ǡ��֡��ı�����Ԫ��ͬ����ȡ�������shou��������ĸ��s����Ϊ���أ���Ҳ���͡��ɡ��Ķ�������ĸ���ǡ�y�����ɴ˵ó����ء������顱���ֵĴ��붼�ǡ�csy������Ͳ����˴����ͻ�������ͻ����Ĵ���������չʾ����Ϣʱ�������Լ�¼���ߺͼ�¼����֮�����һ��ì�ܣ�������Ψһ��Ҫ�������ռ��ͻ��ì������һì�ܵĴ��ڣ�������������ͻ�ʵ�ʵ�֣������˱����ʵ���ԡ�
������������������������������������������������
[14] ������ί�������ֹ淶GF3001��1997�С��ʻ��������ǣ������ɿ������ε���С���ʵ�λ����
����֮���Բ�������ϰ���˵ġ��ʻ������á����ء�����ʣ�����Ϊ���ǵ����ʻ�����һ���ʣ�ֻ�Ǻ�����ϵͳ���������ȥ��δ���ķ�չ��ʷ������һ���ض����е��ôʡ��ڼ���ʱ���������õ��ڹ���Ͽ��֣���ʱ��û�бʣ����ҴӼ��ĵ�������������Ҳ�����ں�ƽ��ֱ�ıʻ�ϵͳ����Ȼ�����С��ʻ���������Լ���Ӧ�ĸ��ֻ�е������Եļ�¼��������˴ӵ����ʵ�ת���Ժ��ʻ�������ʲŵ��Բ����������ǹ㷺ʹ�á����Ӽ�����ں����ִ�������õ��㷺ʹ�ú�����ʹ�ø��ֱ��뷽��ͨ��������ļ������뺺�֣��Ѳ�����һ��һ���ؽ����ˡ���ʾ������ʾ���ֺʹ�ӡ����ӡ����Ҳ���ǰ��ʻ������ˡ�ʹ�á����ء�����ʣ����Գ�Խ��ʷ�ľ��ޣ������ں����ַ�չ�ĸ�����ͬ��ʷʱ�ڡ�
[15] ��������ֵ䡷���Ĵ���������������磨1986 �� 1990�������p3172���H��������˵��. �H���������H�����UҲ���Ӷ���������������������ܳ����
[16] ����������Ԫ����ϸ����������ij���Ȼ�����岿��С�顷����������ͬ���о�����5��������Ļ�������������˾2004����档
[17] ��ָƽʱ�����ġ�Ʒ�ֽṹ����֮���Բ��á�Ʒ�֡�����ʶ��á�������������Ϊ������Ϊԭ���á�Ʒ�ֽṹ�����������������Ԫ����λ�ù�ϵǷ�ס���Ԫ��ļ���λ�ù�ϵ�롰Ʒ������ͬ�Ļ��С����������Ρ������ڡ������ȣ������롰Ʒ���ڸ�����Ԫ����λ�ù�ϵ�����������ȫ��ͬ��̸�����ĸ����ߴ����ԡ�����һ���֣�����Ҳ��������Ԫ�伸��λ�ù�ϵ��֮Ϊ�����ֹ�ϵ���������ֹ�ϵ���������ֹ�ϵ�����������ߣ����˵���ɡ�Ʒ���ֵ��������ڡ��γɡ�Ʒ���ֹ�ϵ���ͳ�������ѭ��˵�������ø��ּ����������ȷ�������ּ�������Ԫ�������ġ�����������ʣ��Ƚ�ԭ�����ᷨҪ����Щ��
[18] �����������ı�������ij�Сƽ�����ݽṹ�����Ͼ���ѧ�����磨1994��2�°棩��
[19] ���ı�����ʽ�С��ȸ������������и�������������������������ȵȡ��ں����ֵļ������������в��ú�����ʽΪ�ã�����չ�����ۡ�
[20]��������ֵ䡷���ġ�P2359������������˵�ġ�����������Ҳ�����ģ� ![]() ������������P4098��
������������P4098��![]() ��������ying����
��������ying����
 ����
����
 ��
��