





主要是因为你打拼音,不用形码输入法。:cry:
在这里等着我呢! :cry: :cry:
我是理科生啊,文科的精髓不是那么容易弄明白的~~:loveliness:
请 关注133楼这个 “新面孔”
原帖由 Luxgum 于 2011-5-13 11:07 发表 133楼http://www.pkucn.com/images/common/back.gif无聊了,把浮云吹成神马 也好耍!
金岷氏曰:在由 jr0jr 先生发起的讨论学问的本论题里,参与发帖的网友们都是认真谈论学问,各抒己见。出来了这样一个 署名为 Luxgum 的“新面孔”,发了如上引用的这份帖子。
很明显,这是一份来搅局的帖子!硬要挤进来扫大家讨论学问的兴。 这不,居然是到这个学术论题讨论里来“好耍”来了。
奉劝这位 新面孔的要“好耍”的先生,您可以提出您的学见,参与大家的讨论。如果没有自己的学见,也可以当读者、观众,是个正经的网友;万不可屡屡发这种无端搅局,惹人讨厌和嗤笑的 为了自个儿“好耍”的无用帖子――不发这种帖子,没人会把您当作文盲或者哑巴。
更何况,您有学问本事把这个讨论汉字字形结构算法的论题,搅得黄吗?!
[ 本帖最后由 金岷彬 于 2011-5-14 10:39 编辑 ]
如何衡量析构(建构)结果
热心关注本贴的坛友们提出了这个问题。我有个小见识,说出来也不怕大家笑话,真的是抛砖引玉:loveliness:既然使用拓扑的表示方式(点线的空间位置关系),就很容易在一个有限平面内使用分段直线函数描绘。其实可以使用纯数学的方法,计算汉字原型和拓扑表现型之间的相关性。原理上,这个是没有一点问题的。
如果使用数字计算机,还可以有些加速的小窍门。我们既可以规规矩矩地先定义直线函数簇,然后用离散近似法计算相关性,也可以先把直线函数簇离散化,然后再计算离散后线段的相关性。具体的做法就是在大分辨率下把拓扑结构数字化,使用点阵结构来进行比较。综合考虑形似度的真阳性和假阳性两面,作出一个量化的评估。
[ 本帖最后由 jr0jr 于 2011-5-14 21:12 编辑 ]
求助!
原帖由 客串客串 于 2011-5-15 19:14 发表 http://pkucn.com/images/common/back.gif应该提供给人们一种能够在电脑上十分方便地造字的技术手段,然后解除法律上对造新字的禁锢,让汉字获得一种自然演进的环境与土壤,如此,经过长时间的自然演进,汉字才能完成信息化的蜕变。
我知道eforth编辑器可以做到。自己鼓捣一个LaTex插件也可以做到。
再者,有没有什么网页浏览器插件也可以呢? 金岷彬 又在 设啥局 蒙人 ?
咋 被我 轻巧的一句话就给搅黄了呢?
你也太寒碜了吧!
==========================
更何况,您有学问本事把这个讨论汉字字形结构算法的论题,搅得黄吗?!
--------汉字字形结构算法!!!
我说过无数次,汉字字形最大的特点就是一个字'乱',没有规律 有个鬼的算法!
当然,有人说:世间最好画的 就是 鬼,画得越乱越怪越像鬼。
受到金岷前辈的启发,第二套拓扑员可以改为下图所示,其中第四行专门表示如上中下,左中右结构的字形。仍然是二元输入,所不同的是,上下和左右两部分作为一个物理上分离、逻辑上连接的整体。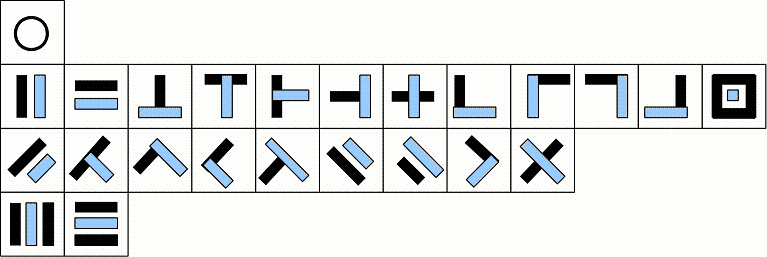
(西星点评: 这个有点意思了
楼上是否缺少拓扑元
水登
水
登
水
登
看着两个字,楼上是否缺少拓扑元?
拓扑元可不是为了动态构字的,美观可与它无关。
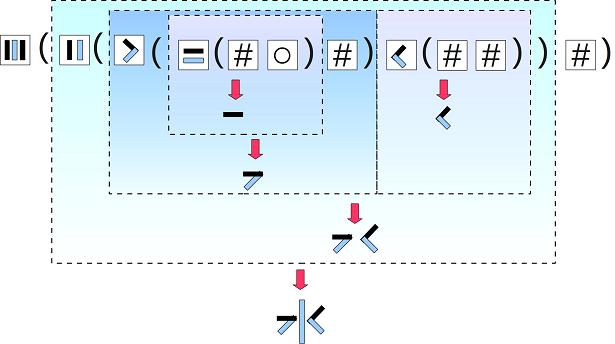
我这里手动析构了一个水字,其实这个活儿本来应该是计算机用启发式搜索来干的。
登就算了,客串先生不是说了么,只弄汉字部件~~
[ 本帖最后由 jr0jr 于 2011-5-17 21:51 编辑 ]
(十)拓扑元的正交性和冗余度
正交性的问题可以简化为,两个拓扑元之间是不是有包容关系。假如使用第一套拓扑元集,其中“田”就可以看作是所有其它元素的根元素。也就是说,田,其实可以用其它字元素构建。那么田本身就是百分之百的冗余。所以第一套“井田”拓扑元的结构上的冗余度是非常大的。
第二套拓扑图元的冗余度应该很小。似乎没有任何一个拓扑元可以由其它两个拓扑元组合建构而成。但是从构造结果的角度上看,存在不同的拓扑元组合可以构建出相同的结果。就像1+4=5,2+3=5,等等。这是一种功能上的冗余,或者简称它为多态好了。
回复 146楼 的帖子
拜读了 146楼的 “水”字由基本笔画组成字形(或部件)的算法表达式,受到教益。并提出襄助意见,供参考:1,原算式的表达,采用了“非通用性字符”,这不利于网友们在网络上交流时的键盘输入。可以先行制定并公布一个“结构算法代码表”,那么每一种基本的构字算法,只用一个字母就可以方便地表示。如果始终要采用146那样的结构表达式,那只能用“图形方式”来交流,显然没有文本方式交流方便。
当然,jj 君在介绍自己的观点初期,采用图形方式来形象化地阐述,是一种很直观的方式,有很好的效果。在初期介绍的时候,也是一种必要的形式。
2,金岷氏觉得,各种汉字构字运算表达式,能否向着用 形式语言 的格式来表达方面走。这是因为,按照形式语言的严密逻辑结构,能把汉字的字形运算表达得清楚一些,逻辑严密一些。采用形式语言来表达的汉字字形组字运算,也能方便地让外国的汉学家们了解中国学者的研究状况;特别像 jj君,就在海外工作,应该让海外的学者了解 jj君用计算机研究汉字 的学术动态。
惭愧,金岷氏曾经尝试做过用形式语言来表示汉字构字算法的探索,那是将近二十年前的事,后来中断了;而且也是受到字形分析与组字的先行者们的启发。现在虽然有继续下去的想法,而且也在啃新版本的《形式语言与自动机理论》(清华大学版,2007),但是啃得很费劲。jj 君如果有这方面的基础,不妨试试;笔者更盼着 jj 君或其他通晓形式语言的学者,能提出新的表示 汉字构字算法的 形式文法 规则,和具体的形式语言表达式,那么金岷氏或许跟着往前走,减轻啃书的劳动量(见笑了)。
[ 本帖最后由 金岷彬 于 2011-5-21 07:50 编辑 ]
原帖由 金岷彬 于 2011-5-14 09:28 发表 http://www.pkucn.com/images/common/back.gif
金岷氏曰:在由 jr0jr 先生发起的讨论学问的本论题里,参与发帖的网友们都是认真谈论学问,各抒己见。出来了这样一个 署名为 Luxgum 的“新面孔”,发了如上引用的这份帖子。
很明显,这是一份来搅局的帖子! ...
金先生,你别指望他会认真和你讨论问题,他没有这个能力也没有这个智商,他本身就是来搅局的。
在语言文字漫谈版块,讨论轻声读音问题,他就在搅局――不懂又装懂,充当行家,满嘴胡诌,又闹笑话:什么是词组,什么是实词、虚词,他都分不清。在我提供强有力的字典对汉字(或词组)的读音证据面前,他都敢耍赖和抵赖。
更荒唐的是,我说“某些字,在词尾(我列举了几条规则)勉强可以都轻声,也就是说一般不读轻声”。
我这里的【一般不……】,是【一般情况下不……】的简略语。他竟然以他超强的天赋,凭这句话推断出“【勉强】=【一般不】”这样的鬼话来。还狡辩说是我说的。
他一边极力否认我对轻声读音归类的说法,一边又不自觉的套用我的说法,举出的例证符合我的说法。
你说,凭他这样的智商,凭他这样的学问和水平,他能讨论什么出来?
那边关掉(屏蔽)了他的贴子。不然要把他拉出来献献丑。
[ 本帖最后由 星空一号 于 2011-5-21 09:24 编辑 ]
再简化一下:
http://www.pkucn.com/viewthread.php?tid=107814&page=2#pid1218782437
(因此,选定适当的部件集,至少,楼主的这样想法可以改变一下了:
汉字结构确实可以表示为:
●●●●●
●●●●●
●●●●●
●●●●●
甚至更为简单)