





�����༭�����������£�
����
�š������ߡ�ľ��δ��ĩ�����š������ߡ�ľ��δ��ĩ����
�š������ߡ�ľ��δ��ĩ����
�š������ߡ�ľ��δ��ĩ����
�š������ߡ�ľ��δ��ĩ����
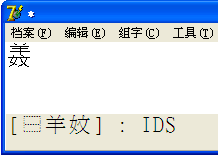
��һ�����˵��һ���ڵ����������Ϸ���ıʻ��� �S
�S
�S
����Т
����Т ��С�Ϳ������ˡ�
ԭ���� yywzw05 �� 2011-5-12 17:50 ���� http://www.pkucn.com/images/common/back.gif
���ֵĽṹ���ر�һ���ڵ��ϲ���������������ϵıʻ��Σ��������������𣩣�JJ�Ǹ���Ů���ֺܱ�Ť������������:cool:
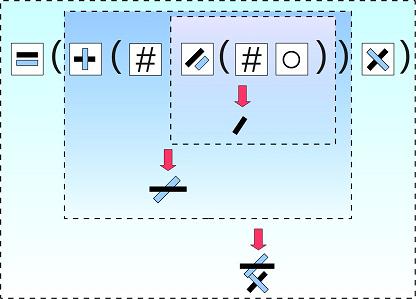
��һ����������Ȼ�ܳ���˵���ģ�����Ԫ����Ϊ�����ֶ���Ϊ�����֡���������Ԫһ��Ū����Ů������
������������������ŵ��������յ��⣬���ֲ�֪�����ᵽ������λ���ˣ��о����е����µ���JJ�ܷ����������ͨ��˵�������ǻ����̷�����һ��ѧ�ĿƵģ�ʵ�ڲ�֪����զ���¡�:shy:
ԭ���� л��� �� 2011-5-12 17:55 ���� http://www.pkucn.com/images/common/back.gif
�����༭�����������£�
�����ֺ�ƽ��ֱ������ƴ����ׯ���֡�����ƴ�֣�Ҫƴ�úÿ��������Ѷȸ���
���ţ�һ�������
�����̣�genetic programming�� GP����һ���ܵ��ݻ��������ļ�����Զ���̵��˹����ܼ����������ڵ�GP�У������ָ������ݵ�ֵʹ����״�ṹ����֯��ʽ������������
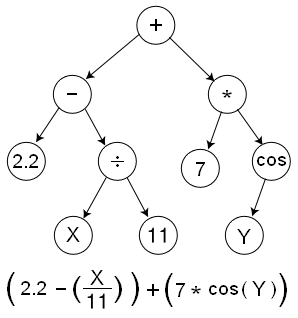
���ڵı����Ҫ�ǽ�����Lisp�����ϵġ�����һ�ֺ���ʽ������ԣ�Functional Programming����������Ҫʹ�����˹������ϡ������������֮ǰ�����Ĺ��캺�ֵ���Щ��ʽ�����Ƿdz����Ƶġ�
��һ������������������ļ�����̣����ȣ������������n���������ʾΪn�����ݼ��������ͣ���Ȼ�����ͨ����ε�������ֱ�õ����ǵĽ���������ͣ���ѡ�������ֵ������ԭ�ͣ���ӽ����Ǹ��������õĻ����ͱ���������������ͱ�ɾ������һ����������Ȼѡ���ᄎ�����������������Ϊĸ�������������������Ӵ������Ӵ���ĸ��ֻ�����������С����ٴ�չ�����и���Ļ����ͣ��������ǵı����ͺ�����ֵ�IJ�ࡣ�ٴ���Ȼѡ���ٴ�������Ů��������˵�����ֱ������������������һ��Ԥ��IJ��ֵ��Ҳ�����ǵ����Ĵ������ȵȡ�
���е���һ�У������Զ��ģ�����Ҫ�˹���Ԥ�����ԣ�����һ��������һ��ĺ��֣����ᱻ������ʲô���ӣ�����ȫ����Ԥ�ϡ�
[ ��������� jr0jr �� 2011-5-13 03:10 �༭ ] ԭ���� �ʹ��ʹ� �� 2011-5-11 22:08 ���� http://www.pkucn.com/images/common/back.gif
�����Ǹ�ԭ��Ҳ����ÿ���������ܹ᳹���ġ����仰��˵����ԭ���ر��Ͻ������ң�560��������ȷ����Ҳ��ֹ�������η�������أ�������������Դ��������ϰ�ߵ����ء�
�����ⲻ����ڸ����560�����淶��δ�� ...
��ͬ��
�ʹ���ʦ�ԡ�����������ʶ�����ԡ� �е����ơ�

�ظ� 129¥ ������
λ�ã�����С��ԭ���� jr0jr �� 2011-5-12 21:40 ���� http://www.pkucn.com/images/common/back.gif
�����̣�genetic programming�� GP����һ���ܵ��ݻ��������ļ�����Զ���̵��˹����ܼ�����
�����ڵ�GP�У������ָ������ݵ�ֵʹ����״�ṹ����֯��ʽ������������
110774
���ڵı����Ҫ�ǽ�����Lisp ...
лл���⡣
�ظ� 131¥ ������
���ؿ������������ǵ�һ��ʹ�ú�����ͻ����̵���Ҫ���ݣ����в�������֮�����������ָ���� �����ˣ��Ѹ��ƴ������� Ҳ��ˣ�� ԭ���� �ʹ��ʹ� �� 2011-5-13 10:08 ���� http://pkucn.com/images/common/back.gif�Զ����������ڲ��ṹ��˵��IDS������ṹ����ͬ�������õġ�������Щ�ṹ���ӵĽ����Բ�����IDS������ã�YY������Ҳ��һ���ܽ���á��硰��꣬�ң������ϣ�Ҳ���죬Ȯ���⣬Ů��붡�֮�ࡣ
ԭ���� �ʹ��ʹ� �� 2011-5-13 11:03 ���� http://www.pkucn.com/images/common/back.gif
�ǵġ�������ܳɹ������ⲿ�ֺ��ֻ��߲�������ô�����������ߺ��ֵ��������Ͳ����С��һ���ˡ�
����ʵ������Ѿ����ˡ������ָ���Ҳ�������٣���7ǧ�������ٶ��� :D
ԭ���� jr0jr �� 2011-5-13 21:34 ���� http://www.pkucn.com/images/common/back.gif
����ʵ������Ѿ����ˡ������ָ���Ҳ�������٣���7ǧ�������ٶ��� :D
���ڱ������66¥��˵�����α�Ҫ�����߰�ǧ�����أ�ɽ��ȫϢ���뷨��300�ָ����߲���560��������Ū�����Ͳ����ˡ��ָ������߲������ܸ㶨���ٴ���Ŀ�ĺ��ּ�Ҳ���ڻ����ˡ���