





三分法则
三分法则
三(十丨丨)

三(丨十丨)
:cry: 横落到三分的边界上怎么办,十的横并不要求在正中间啊。 还有“士,土”,“八,儿”,“用,甩”,“末,未”
自相似多层次九宫嵌套结构分析仪
如果有必要,这有什么困难呀咱送楼上二位一件法宝,
自相似多层次九宫嵌套结构分析仪:

原帖由 CFit 于 2011-5-9 11:53 发表 http://pkucn.com/images/common/back.gif
但改字是要有依据的,至少历史上出现过这个字型,并且有一定的认可程度。汉字是人类文化的一部分,不依赖于任合工具和算法,计算机和各种算法是为汉字服务的,要服从汉字的历史和规律,而不是汉字服从计算机或某种算法。
汉字是人类文化的一部分,不依赖于任合工具和算法。您说的非常好!
本兴趣组的目的,是希望可以用工程分析的实验数据告诉大家,汉字在信息承载方面的能力。汉字的演变当然要我们使用者来主导,不过计算机是量化分析的一个重要工具。不是服从计算机和算法,而是借助计算机和算法。换句话说,“改不改字”跟我们这个兴趣组没有关系,那要全国老百姓说了算。但是,我希望可以通过本次研究,可以对汉字的演变起到量化分析的作用,在需要的时候,向大众提出建议和被选方案。
说清楚了么?:D
[ 本帖最后由 jr0jr 于 2011-5-9 17:56 编辑 ]
原帖由 yywzw05 于 2011-5-9 15:42 发表 http://pkucn.com/images/common/back.gif
如果有必要,这有什么困难呀
咱送楼上二位一件法宝,
自相似多层次九宫嵌套结构分析仪:
有意思。所以,日和曰就可以分离开了。同理,士和土,末和未,是不是可以让那两横在不同的尺度下叠加?
不同尺度叠加,自然耗费更多的运算和迭代层次,也可以作为衡量形似度的一个参数。
[ 本帖最后由 jr0jr 于 2011-5-9 17:58 编辑 ]
闲话
早先的OCR软件是不太好分别日和曰、末和未的,尤其是手写体,每个人都不一样。所以,想要区分必须通过高一层的语义判定。比如,套用《武林外传》的名言:子曾经曰过。 计算机的实际操作描述如下:假设,用yy来代替这个有待识别的汉字(两个英文字母存贮大小等同于一个汉字)。计算机给定识别范围为{日,曰}。通过现代汉语语法分析,曾经yy过,显然yy应该是一个动词。
经过判断,发现曰和日都有动词的义项。那就要看“子”作为主语,是参与曰动作的频率高,还是参与日动作的频率高。通过统计分析发现,“子”参与曰动作的频度是0.8,参与日动作的频度是0.2,那么基于概率原则,上文应该是:子曾经曰过,并且给出置信概率为0.8。
看,如果汉文可以在“字”的这个级别就被高效的识别出来该多好~~
蒙了
J君呀我喝了点酒
感觉他们蒙了,呵呵
您说是不是我蒙了呢 我就糊涂了,什么时候开始叫我 J君了。。。不是JJ么?。。。:o
谁不蒙啊,汉字长的这么复杂。:P
冗余冗余
今天yy先生发贴说:原帖由 yywzw05 于 2011-5-10 02:34 发表 http://www.pkucn.com/images/common/back.gif
冗余,必要的冗余,没必要的就不冗余。
前两天谢振斌先生也说过:
原帖由 谢振斌 于 2011-4-30 18:52 发表 http://www.pkucn.com/images/common/back.gif
此外,提一点,作为文字,一定的冗余是需要的,否则无法识认和学习,也不利于抗干扰性能。
看来冗余是个大问题。今天还跟鼠明先生聊,怎么去摸索一个合理的比率,在简化度和识别度中间找折衷。他建议我向金岷彬先生求教。金先生曾经撰文谈过这个问题,可惜时日久远,已经淹没于帖海之中。
金先生,如果您还在关注这一贴,烦请您再谈谈好么?
原帖由 yywzw05 于 2011-5-9 15:42 发表 http://www.pkucn.com/images/common/back.gif
如果有必要,这有什么困难呀
咱送楼上二位一件法宝,
自相似多层次九宫嵌套结构分析仪:
任合两个字,只要有差别,都可以找到办法区分,这个不难。但是,哪种方法能在开始就把汉字的特性定义好了,之后不管出什么样的字,原来的表示方法都能清楚地表示这一个汉字,而没有歧义,这才是问题的难点。也就是说是否真正找到了汉字的本征特征,任你再出现什么字,只要人能看出区别的,原来的方法就能区别,而不是看到差别再增加一种特性,再细分一下就能区分了,这样的办法会的人很多。
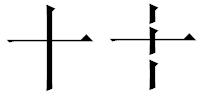
比如,在日本的edanashi出现之前,十字是不是用一(十)就可以表示了,但edanashi出现以后,一(十)就分不清是十还是edanashi了,十就需要用三(丨十丨)表示。但是,之前数据库里的一(十)到底是十呢,还是edanashi呢?
现在用三(丨十丨)表示十,下面两个字是不是都是三(丨十丨)啊,不要告诉我你还有办法区分,我想知道的是以前的“三(丨十丨)”表示下面两个字是不是都对。
我们是不是该选择去美化符合认知心理学的计算机字体呢。使国人看得快、看得准,是不是才是我们最终的目的呢?
什么字体才是你认为的“去美化符合认知心理学的计算机字体”?是YY先生的井田字体吗? 原帖由 客串客串 于 2011-5-10 12:52 发表 http://www.pkucn.com/images/common/back.gif
什么字体才是你认为的“去美化符合认知心理学的计算机字体”?是YY先生的井田字体吗?
我不知道。。。所以才去探索。要请有条件并且有兴趣的认知心理学实验室一起来研究探讨。
如果什么都弄好了,我也就不用来论坛了。推销产品太累,我干不来。:cry:
CFit先生好勤勉!
三(* * *)好像是有问题。它表示不连接的并联。= ∧ ⊥ X 是最主要的两两关系。抛砖引玉一下:使用我的语法,使用YY先生的“字元”,我可以用王(O,#,#,O)来表示对称的十。用王(O,#,#,|)表示长腿十。不过,这也是权宜之计,还要集思广益才善!
CFit先生如果嫌一小时一帖的限制讨厌,可以用站内短消息发给我,我帮您贴出来。在下只是代劳,著作权还是在您。
有关语法,在这里。
原帖由 jr0jr 于 2011-5-8 05:26 发表 http://www.pkucn.com/images/common/back.gif
终结符用#表示,空结构用O表示。两个的作用不同。
O是拓扑元集中的一个元素,任何引用O的操作返回一个空白。#是为了终结某一个迭代操作,引用#则使用元操作本身的线条。
比如 二(o,o)我们会得到一篇空白 ...
[ 本帖最后由 jr0jr 于 2011-5-10 18:33 编辑 ]