��5.3 �����Ķ��� ����˵����Ҫ���˴�����һ����������������·��õģ���ֻ�����������Ĵ�С���߶ȣ�������Ķ��ٵȣ�����������Ķ�����һ��������ʧ�����ⲻ������˲����⣬���ǽ����ò������Ҫ�������ּ��е�ȫ������������Ҫ֪�������ı������ԡ�����˵�������Ķ��壬Ҫ�������Dz����ı������ԡ� һ�������ı������� ������Ϊ�������ı��������ж������ɷ����Ժ���Զ����ԡ��ɷ�����ʹ���ֲ��Ϊ��������Զ�����ά���˲����Ĵ��ڣ���Լ������Ϊ�����ʻ���ƴ�������еĵ����ʻ���ֻҪ�пɷ����Ժ���Զ����ԣ�ҲӦ�ó������Dz����� ���ڡ��ˡ��Ǻ��֣����ڡ�����Ʒ���ӡ��ڡ��Ⱥ����У������Dz�������ح���]�����DZʻ������ڡ������ɡ������ס������У������Dz�������˾���ʡ�ͬ�����ϡ������ס�������Ȯ���ڡ����ȡ�����Щ�����ж�������Զ����ıʻ�������ͳ�����Dz�����ɵĺ����а˰ٶ����ָ���������ֿ⣬�����ں�����һ��С��Ŀ������������������������κ����ò��������� ��һ���dz��֡������ں�������һ���ʻ�����ʡ��������ǡ��ա��͡�һ����ʣ���ƴ�ɵġ����ա��͡�һ���������ڶ��dz��֣���������ɡ�����֮�����ֻ���ϡ��ա��Dz����������ϡ�һ��Ҳ�Dz����ƺ��е�˵����������������ټ�һ���Ϊ��ب���ָ�����ν��ͣ��������ʻ���������һ�������������������ʻ��� �������ڡ�ƴ��һ���������֡����ڡ�ֻ�ǡ�������һ�����֣������С��ڡ��Լ��������ˣ���������ʹ�Լ��Ĺ����ˣ����ڡ����ˡ������IJ�����������ڡ������ں��ֵĶ����У����ڡ����dz��֡����������Է�Ϊ�������ڡ������������ڡ��Ĺ�ϵ������һ����Զ����Ĺ�ϵ�������������ڡ�֮������š���Զ������Ĺ�ϵ��������ǾͲ����˿ɷ����ԡ����ǣ�����������еġ��ڡ����Ͳ����ٷ��ˡ���Ϊ�ٷֵĻ������ڡ��ͱ�ɱʻ��������ͱ������ˡ��´�������˵���Dz����ġ������ٷ֡������ԡ������ٷֵ����ԣ��Dz����������ʻ���ʻ�֮��Ļ����ṹ��ϵ���ɵġ������硰�ڡ��������ʻ�������ӣ��γ�һ����հ�Χ�ṹ�����ֽṹ���Ǻ��ֲ����Ļ����ṹ���Dz��ܲ�ֵġ����ɴ˿�֪�������в����벿���Ĺ�ϵ�����Ծ��пɷ����Ժ���Զ�����Ϊ���ݵġ����ijЩ�ʻ����пɷ���ĺ���Զ������������ԣ���Ӧ�������������������ϱʻ����ɵIJ�������Ҫ����һ�ֽ����������ʻ��ṹ������Լ���ɷ����ԡ��͡���Զ����ԡ����ô�С�Ͷ�����Ϊ�����ı����ǷDZ��ʵģ��ò���������Ϊ�����ı������DZ��ʵġ� ���߱��������Եıʻ������� ��������Զ�������ʻ�����һ����֣�û���������������ԣ��Ͳ��ܻ����������� ��Ҳ���õ�֤���������ϵ����ԡ����ڡ�ؤ���Լ��������ж�����ˡ���ˣ������㲻�㲿����Ӧ�����ۡ��������Ļ�����ؤ���־�Ӧ�û�Ϊ��������ô����ҪȨ�����ס� ��Ҳ���õ�֤���������ϵ����ԡ����ڡ�ؤ���Լ��������ж�����ˡ���ˣ������㲻�㲿����Ӧ�����ۡ��������Ļ�����ؤ���־�Ӧ�û�Ϊ��������ô����ҪȨ�����ס� ���Ȩ����벻��������أ����ԡ�ؤ��Ϊ��������ؤ����Ϊ�� ����������һ������֤���IJ����������ԡ�ؤ���IJ�־���Ҫ���⣬���DZ�һ�棬������ʹ��ؤ�������������ˣ����������ˣ����ϱ����Ŀ�ģ�ʹ���ֳ�Ϊ�������֣���������һ�档���𣬡�ؤ����Ϊһ�����������Եõ�����Զ�������֤�����ڶ������ֿ��У���ؤ��ƴ���ˡ��ơ��֣����롰�R�� ����������һ������֤���IJ����������ԡ�ؤ���IJ�־���Ҫ���⣬���DZ�һ�棬������ʹ��ؤ�������������ˣ����������ˣ����ϱ����Ŀ�ģ�ʹ���ֳ�Ϊ�������֣���������һ�档���𣬡�ؤ����Ϊһ�����������Եõ�����Զ�������֤�����ڶ������ֿ��У���ؤ��ƴ���ˡ��ơ��֣����롰�R�� �����������м������Եļ�϶���ڲ��������ϣ���������Ҳ���ǶԲ�������û�в���Ӱ�죩������Ҫ��ؤ�IJ�ּ��Խ��⣻���𣬲�����ʵ�ֽ������ų����Ե�Ŀ�ġ�����������Ҳ�������룬����һ������������Ƿ��ࡣ��ؤ����Ϊ���������Ǻ��Ѱ�������ijһ����𣬼�ʹ�ܹ����룬Ҳ�Ǻ���ǿ�ģ��ͻ����Ӽ��䡣�����������Ѿ������ֳɵ���𡣰�������ıȽϣ���Ȳ���������Ҳ���������������в��Եĵط��������Ҫ���һ�������ˡ���֮�������Ǻ��ֵġ�Ԫ�ء���ȷ��һ�������������һ�����ֵIJ�֣����Ǻ�������£����ܵ������ġ� �����������м������Եļ�϶���ڲ��������ϣ���������Ҳ���ǶԲ�������û�в���Ӱ�죩������Ҫ��ؤ�IJ�ּ��Խ��⣻���𣬲�����ʵ�ֽ������ų����Ե�Ŀ�ġ�����������Ҳ�������룬����һ������������Ƿ��ࡣ��ؤ����Ϊ���������Ǻ��Ѱ�������ijһ����𣬼�ʹ�ܹ����룬Ҳ�Ǻ���ǿ�ģ��ͻ����Ӽ��䡣�����������Ѿ������ֳɵ���𡣰�������ıȽϣ���Ȳ���������Ҳ���������������в��Եĵط��������Ҫ���һ�������ˡ���֮�������Ǻ��ֵġ�Ԫ�ء���ȷ��һ�������������һ�����ֵIJ�֣����Ǻ�������£����ܵ������ġ� �ĸĻ���һ��648���������嵥������ʹ��Ƶ��ͳ�ơ������嵥Ϊ���������α�����ƣ��������ٵĹ��ס��������Ҳ��������һ���ָ�Ƶ��ͳ�ƣ�ѡ����99���ָ�������ѡ���ָ�����涨������ѡ���ָ������ײ��еĻ����ײ��ˣ��涨��ij�����Ƶ��ָ�����������涨ʹ����������кܶ�ļ������� �������ָ�������Ϊ���ֵ��м��Σ��ṩ�����α�������õġ���ϧ������͵��ָ���Ϊ��������Ļ������ϲ������á�����ͳ��Ƶ����ѡ�������ָ��������γ�һ��ϵͳ��̫���ң�������̫�࣬ѧϰ�����ѣ�һ��ѡ������û�б��������������⡣����ͬ��ѡ�������Ϳ��Գ���ͬ�ķ���������������Ƶ�Ȳ���һ�¡��еIJ�����ɳ����֣�ʹ��Ƶ�Ⱥܸߣ�������Ƶ�Ⱥܵͣ�ѡ��ѡ�������⡣����ѡ�ø�Ƶ���������ײ��������ǵIJ������ָ������Ǹ��ݲ����ı������Եõ��ġ� ���ݲ����������Եõ��IJ������ں�������ʹ����һĿ��Ȼ����Ϊ�����Ϻ��ֽṹ���ɣ�Ҳ������֪��������������ѡ�����IJ������ֽ�ʱ�͵�����涨��������ס�� ���������������� �������¶�������и������������¡���������ô��ʮ�����壬˵������ѧ��ͱ���磬������Ϊ��������壬Ϊ��ֶ���ֵĴ������������ִ�������ĸ���ԭ���Dz����ⲿ�������ϵͳ�ԡ� �������¶��壬����Ҫ֪������ΪҲʲô��������Ϊ�������¶����Ŀ����Ϊ���õ������嵥�������嵥���Dz����Ķ����������嵥�Ϳ��Թ��ɳ����ֵIJ�ֹ���Ҳ���Ը��������ࡣ��ˣ���������֡������Լ��������IJ�����������壬��������ѧ�ģ����Ǻ������α������ѧ�ġ�ͼ9�����ʾ��ͼ�� 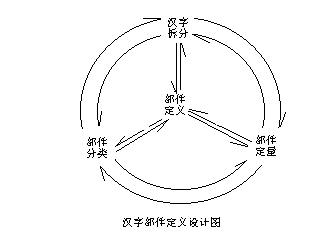
ͼ9 �����������ͼ ͼ9��������������ĵ�Ҫ��Ҫ��������ֵ�ԭ��λ�����������ݣ��Ľ��ͷ���ķ�����������Լ����������ƶ�����ͼ����������֡����������࣬���߹�����һ���Բ�־����������Զ������Ʒ��࣬�Է�����Լ��ֵ�ϵͳ�ṹ�� ˵����һ�㣺û�в�֣��ж��ٲ����Ͳ���ȷ��������������û�ж������Ͳ��ܽ��з��ࣻû�з��࣬�Ͳ�����Լ��֡�����һ������������Լ��ѭ��Ȧ����֡����������࣬���������ڶ��壬����Լ����IJ����� ͨ��������ͼ�����ǾͿ��ԡ���ͼ��������������ͼ�������¶��塣 ������������ �������Ϸ�����������Ϊ�����Ķ���Ӧ���ǣ�ƴ�����ֵľ��пɷ����Ժ���Զ����Ļ�����Ԫ�����ʻ��ṹ�������ʻ�����������ɼ������ı��������ж���һ�ǿɷ����ԣ�������Զ����ԣ���Զ����������ڱʻ��ṹ���������ǿ��Զ����ϵĶ�����ƽ������գ������Dz��Ƿ���Ҫ����ͼ10��ʾ�� 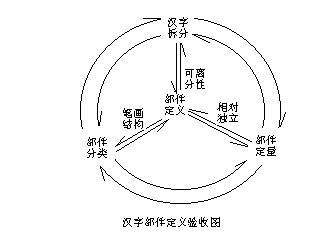
ͼ10 ������������ͼ �����������£� ��һ���ɷ����ԡ��ɷ������Dz����Ķ�̬���ԣ������벿��֮����ƴ�Ϻ��ֶ�������϶�����ּ�϶���Dz�ֵ����ݡ� ��϶���Է�Ϊ���Լ�϶�����Լ�϶�� ���Լ�϶��ָ�������벿��֮�䣬�����ԵĿ���һĿ��Ȼ�ؿ������ļ���� ���Լ�϶��ָ���ߣ� 1��������ͬ�ij��ֲ���֮�䣬�硰�š��ġ�ʮ�������ڡ�֮�䣻 2�������ʻ�����ͬ�ıʻ��ṹ��֮�䣬�硰ʾ���ġ���������С��֮�䣻 3��������ͬ�ıʻ��ṹ��֮�䣬�硰�硱�ġ�Ի����Χ��������ʮ�����棩��֮�䣻 4��һ�����ֲ�������һ���ʻ��ṹ��֮�䣬�硰ռ���ġ� �������ڡ�֮�䣻 �������ڡ�֮�䣻 5��һ��Ʋ����һ���ʻ��ṹ��֮�䣬�硰�ԡ�ǧ���ġ�د��Ʋ�ʣ����롰Ŀ������ʮ��֮�䡣 6���롰�ꡱ����ĺ����ӻ��ཻ���硰ꫡ��ҡ���������ʵ�Ƿֿ������������������ǵıʻ����ƺ�λ����ͬһ�����ϣ�Ϊ����д������֣����㣬����һ���ˣ�����������Ҫ������ǣ�����ָ�����ԭ������ò�� 7�������Ͳ������еIJ������ʻ���ʻ�����ʿ飨�ʻ�����ʿ�֮��Ҳ���������Եļ�϶��������֮�䣬���ƽ�У���������ľۺϣ�������棬��״���ơ������෴��������һ���ھ��ԣ����������Ĵ�����ʽ���Dz��ܲ�ֵġ� ������ֲ�����ָ��������IJ������硰��ľ���ڡ��ա��ȡ��ʻ�������ָ�ʻ���д�ķ������������¡��������ҡ� ��������Զ����ԡ���Զ������Dz����ľ�̬���ԣ�����ά���˻����ʻ��ṹ�鲻�ٱ��������Ϊ�����ʻ����ֱ�֤�˺������ĵ����ʻ���Ϊ�����ġ��Ϸ���λ���� �ʻ��ṹ����ָ�ʻ���ʻ�֮�乹��������Ľṹ��ϵ�������Է�Ϊ�������ͣ����ֻ������ͺ������������ͣ��� 1�� �ʻ���ʻ����룬�������ͣ� 2�� �ʻ���ʻ��ཻ�����ཻ�ͣ� 3�� �ʻ���ʻ���ӣ�������ͣ� 4�� �ʻ���ʻ���Ӻ��γɰ�Χ���ư�Χ�ͣ� 5�� ���ֻ����ʻ��ṹ��Ϲ��ɵģ���ij�ֻ�������Ϊ���ӵĽṹ��ϵ�����ּ��͡� �ּܵ�������ÿһ��С���һ����ͬ������Ϊ���ӣ�Ȼ�����ӱʻ���ı���Σ��γ�һ��������� ���顱��ָ���������������ϱʻ�Ϊ�����ṹ���ɵIJ������ں����У����ǿɷ���ģ��Ժ����е�����������˵��������Զ����ģ��������������ϱʻ����ɵĻ����ṹ�� �ġ�������������� �������ֻ�пɷ����ԣ���ֱض�Ҫ�ʻ�������Ϊ��ˣ��е��˲Ż���Ϊ���ֵĻ�����Ԫ�DZʻ���ֻ�бʻ����Ų����ٲ���ȥ�ˡ��������Ķ�̬�����������ġ����ǣ����ּ����ͼ������Ӧ�õ�ʵ���������ǣ��ں�����ʻ�֮�䣬��Ӧ����һ���м��Ρ���������ȱ�������Σ�����Ӧ�á�����м��Σ���������Զ����ġ�ֻ����Զ�����������Լ���Ŀɷ����ԡ���ˣ���Զ��������ľ�̬���ԡ� Ȼ������Զ����ĸ������ģ���ġ�����ָ���ıʻ��ṹ��ͻ����ʻ����°�������˵����������һ�����ʻ��ṹ�顯����ô��Ӧ�����������ϱʻ�������Ӧ���γɡ���״��������һ���ཻ��ıʻ���һ���ṹ�顣������ճ���ıʻ���һ������һ���ṹ�顣���������ȳƵ������ıʻ���һ���ṹ�顣�ġ���տ��ڲ��ıʻ�����������ճ���ģ����������һ���ṹ�顣���ڵĵ��һ�㸽��������塢�����ĵ��һ�㸽�����������Ľṹ�顣����8������Ľ����Ѿ���������� ���硰���������������ཻ��ıʻ��ṹ�飻���ӡ�������������ճ���ıʻ��ṹ�飻���������������������ıʻ��ṹ�飻������������������Χ״�ıʻ��ṹ�顣������ȿɺܷ���ط��뿪����������Զ����ġ���ν��Զ�������һ����˼�����������Լ���������������һ�ۿ����������硰����������ǡ��ߡ����ұ��ǡ����������߶����Զ������֡����硰��������Ի����һ����ʡ���Ի���Ƕ����ġ��顱����һ����������ô�죿����һ�ۿ�������Զ����ģ�������Ϊ��������������� �����Լ�϶�IJ���������һĿ��Ȼ�ؿ�����������Щû�����Լ�϶�ġ�����һ���ֵIJ���������������Լ�϶�ĸ�����Լ�϶Ҳ������֪�������ɡ����������ֵĹ����У��ȶ��ǽӴ�һЩ�ʻ��ṹ���֡���Щ�֣��е��Լ�����һ�����ṹ�顱�����硰ʮ��������ṹ�������ڡ�����Χ�ṹ��������ƴ�����Ǹ����š��֣���Ȼճ��һ�𣬰���������Ϊ����Ҳ�Ƿ�����֪�����ġ����硰ʾ�����������͡�С��ճ��һ���������ֲ�ͬ�ıʻ����ƣ���ֿ�����Ҳ���Խ��ܡ������Ϊ��һ������ ���������Ϸ����Dz������ܵġ�����Ϊ������������������Ϊ������Ӧ��������ӡ��� ���������Ϸ����Dz������ܵġ�����Ϊ������������������Ϊ������Ӧ��������ӡ��� ������������ӡ��IJ��ԭ�����ڡ��������������ܣ������ڡ�ء������������ȴ�����ѣ���ֱ�ۣ�������ʶ��ʱ�����������ϰ�������ʲô���������������ѧԺ����������������һ���ܺõ��������㷽����������֪�����ϵĿɽ��̶ܳȣ������ֱ�ʾ�����ֲ���=3���ʿ鲿��=2�����ʲ���=1�����硰��������Ϊ������ʮ�����������dz��ֲ���������������Ϊ6����Ϊ���ۡ��ɡ���ֻ����5����ء�����������ɲ�Ϊ��һ����������һ�� ������ ������ ���������Ȳ�Ϊ�������|��������������������د������������Ϊ�������ǵ�ʶ�ǹ����У��Ժ��ֲ��Ϊ�����Ľ��ܣ���Ȼ�ǣ����ֲ���>�ʿ鲿��>���ʲ������ں����У���һ��������ġ������桰��ְ�������Ǻ��֣����Dz��������DZʻ������������ϼ�����������һ�������ڵ������ڷ����״̬ʱ��������Ϊ���ֲ����� ���������Ȳ�Ϊ�������|��������������������د������������Ϊ�������ǵ�ʶ�ǹ����У��Ժ��ֲ��Ϊ�����Ľ��ܣ���Ȼ�ǣ����ֲ���>�ʿ鲿��>���ʲ������ں����У���һ��������ġ������桰��ְ�������Ǻ��֣����Dz��������DZʻ������������ϼ�����������һ�������ڵ������ڷ����״̬ʱ��������Ϊ���ֲ����� ���ö����ֺ��֣���Ҫ�����������������Ҫ�ܹ������ݵ�����������м���֪���������ݣ������е�����Ϊ�� ��Ӧ����һ�����顱����Ϊ�����Ǵӡ�ֹ���ݱ�����ģ��������˵Ľš������ô������ ��������ˡ� ���ߡ�����Ҳ���ܲ��Ϊ�������顱�ˡ����ء�ֻ����Ϊ���⡱��Ҳ���ܲ����ˡ���ˣ����ǴӺ����зֽ�������������ų�����Էֽ�ĸ��ţ������ǿ���Ϊ��Ŀǰ����£�����һЩ�ʻ��ṹ���š��Ѻ��ַֽ�Ϊ������Ҫ����ѧϰ�ߵ���֪�������ɣ�Ҫ����ֱ��ԭ����������Ҫ�ġ����硰�㡱������ġ��ڡ�������ġ� ���ߡ�����Ҳ���ܲ��Ϊ�������顱�ˡ����ء�ֻ����Ϊ���⡱��Ҳ���ܲ����ˡ���ˣ����ǴӺ����зֽ�������������ų�����Էֽ�ĸ��ţ������ǿ���Ϊ��Ŀǰ����£�����һЩ�ʻ��ṹ���š��Ѻ��ַֽ�Ϊ������Ҫ����ѧϰ�ߵ���֪�������ɣ�Ҫ����ֱ��ԭ����������Ҫ�ġ����硰�㡱������ġ��ڡ�������ġ� ���˵ı��壩����Ӧ����ֲ�������ô���ѵ��еġ����������Ҳ�������ܡ� ���˵ı��壩����Ӧ����ֲ�������ô���ѵ��еġ����������Ҳ�������ܡ� ���ö���ֽ⺺�֣�����ط�����һЩ���ѣ����硰ϰ���������ٲ�Ϊ���S���������� �������Բ�Ϊ�� �������Բ�Ϊ�� �� �� �������ϡ���Ҳ���Բ�Ϊ������һ��������Щ�Dz𣬻��Dz��𣬿����������ۣ��������ס����硰����ֻ�ڡ��������õ������𣬶���һ����������û��ʵ�����壻�𣬼���һ�����������ڼ���һ�����䵥Ԫ�������ڱס��е��˽��ǿ�����ֵIJ��û�й��ɣ��Ϳ������⣬��û�е�������Ϊ����Щ�����Ǻ����м�����ġ������һ�Ų����嵥��95%���Ͽ���ͨ�������µĸ�������ϵ���������������ͨ������ȷ�������Dz���ȷ����������һ��С�£�����������ģ�����д��Ҫ�����ģ��������������� �������ϡ���Ҳ���Բ�Ϊ������һ��������Щ�Dz𣬻��Dz��𣬿����������ۣ��������ס����硰����ֻ�ڡ��������õ������𣬶���һ����������û��ʵ�����壻�𣬼���һ�����������ڼ���һ�����䵥Ԫ�������ڱס��е��˽��ǿ�����ֵIJ��û�й��ɣ��Ϳ������⣬��û�е�������Ϊ����Щ�����Ǻ����м�����ġ������һ�Ų����嵥��95%���Ͽ���ͨ�������µĸ�������ϵ���������������ͨ������ȷ�������Dz���ȷ����������һ��С�£�����������ģ�����д��Ҫ�����ģ��������������� ���������Լ�϶�ĵ��ʲ���ƴ��ͳ�Ʊ�����856������ �ܡ�һ���С��ࡢ�ܡ������䡢�𡢿��������á��͡��ޡ��顢ب�������á��ա����硢�ɡ��ߡ������ݡ��ˡ��塢�衢ѭ���㡢�����⡢����۪���Ρ��������������㡢�����ڡ��硢ت�������ơ��ܡ���������ء���졢�����ۡ��ᡢ�ǡ��¡������֡����������ˡ��١������ۡ�䡡�ɳ��涡������ġ��졢乡��ޡ��ݡ��١�ʡ�������ӡ��������֡�����Ǣ�������ࡢ�á�����Ѵ���ơ��顢�롢������죡��ꡢǭ���ɡ��ꡢ�塢��¿�����š�ƭ���㡢�ԡ�פ�������������������ۡ��졢�ա������ᡢ�⡢ʻ���ԡ���硢���������桢��顢�ᡢ�����衢�⡢�����ҡ���衢�桢槡��ʡ�棡���������桡�榡��ԡ�������գ�����⡢�졢�ѡ��ҡ������롢�ϡ�Ϻ�����ȡ�Ÿ�����������ѡ������桢�졢�ء��ʡ��ɡ��硢�����ȡ������桢�⡢�硢�顢�����衢�塢�͡��顢Ȼ���塢ʱ���֡�ԧ���졢�䡢�ԡ��ҡ����������ǡ��顢ᯡ������ơ��١������ϡ��š�Ѱ��ߤ�������ۡ��顢���������ҡ������桢�͡���ˡ�ץ���֡������⡢�ꡢ��ڡ�ʰ�������ࡢ�ԡ��š�£���Ρ�����ִ���١�ֿ���ꡢ�ݡ��ޡ��ơ��桢�Ρ��֡�뿡����������������������ҡ������衢�ġ��⡢�̡������롢����ޱ��������ɯ�����������ѡ��С��ס���ݹ��«���롢�̡�ݪ��֥��ݡ���Ρ��顢�����á��֡��ˡ��С��ѡ��ˡ�ݯ�����ޡ��á��ݡ�ҩ���ס�ݧ��ܹ���ס��ա�ݤ���ԡ��ҡ������ɡ��֡��顢�ҡ���������ڮ���͡��̡�ȿ���롢�š��������֡��ݡ�ʫ���ʡ�Ѷ�����������̡��С��衢Ӧ�������ڡ��ҡ������䡢�����㡢�ġ�®���ȡ����������졢롡��ء�������צ�������ס��ᡢ�㡢�ҡ�ƹ���ᡢ�С��̡��ɡ��ʡ�ص��ۡ���ꡢô����������ϵ���ࡢط���ӡ��ɡ��ҡ�ѹ�������̡������ɡ�״�����㡢���������ȡ�����벡�뮡��ӡ��ա�����밡�����뱡�뵡�믡��ȡ��ʡ�����뭡�����볡�����봡��衢�⡢�㡢�������ԡ������������������顢�����������С�����㵡����������䡢�䡢ǡ�������ǡ��⡢𱡢�ѡ��䡢�졢�����¡��顢迡�辡����������顢����輡��ӡ���鿡��ܡ�����髡���鸡�ͩ���֡��졢�ܡ��롢�ڡ��С��ȡ��塢�š�����ͬ��������������ͻ���ڡ�����д���֡��ϡ�ԩ���¡�幡��ס��衢�ء��á�������ড�ॡ������顢����߽��߲�������ء��ᡢ�ɡ����������á��ʡ�������ޡ�����߾���͡��š��������������ʡ������ԡ�Ӵ���š������⡢�ǡ��𡢺��졢��ª�������ġ��ξ��ο��¡���̡��ߡ�赡��ա�����¤���������롢������������⪡�������������̡��䡢�ڡ��ˡ�𭡢�ӡ�����̫��Ȯ��̬���硢�졢�ᡢ�ơ������С��ᡢ�䡢����ư������ȵ�����á�𰡢⾡��ǡ�ͪ��̪�������ǡ����������㡢�á��¡�̻���֡��ҡ�������������Ѽ��ѻ��ڮ���͡��䡢ɰ���롢�����ܡ��硢�ơ������ꡢ�ۡ��ϡ�������ϡ��ʡ��ơ������𡢳ġ��ӡ��ʡ��㡢�⡢�ᡢ�����ۡ������ʡ��롢���������ޡ��������桢����³����������������������塢�ࡢ�������������С������ݡ��������������硢�����ӡ��ԡ��㡢�顢���������ꡢ�������������������ҡ������ܡ��ա������ء����������֡�ݵ����ѡ��ۡ������졢�롢�����ڡ��١������ݡ����������ᡢ먡������졢�⡢ٳ���ϡ��롢�衢�⡢�á��ߡ������С�쨡���������ƫ��ʳ���� ��α�����겡��ᡢ���������ڡ��졢̰�������ٱ���𡢸����ԡ������ޡ�ٿ���ơ��͡��֡��͡�������ơ����������̡�٨�������ԡ���͵���桢��š�ٴ�����������̡����ڡ��š�����笡��̡�ɴ���ȡ������ࡢ�����ҡ�Լ���͡��ꡢ�ȡ�������������Ϯ���á�¢�������ϡ�竡���������˿��ة���ᡢ禡����������á��¡��ǡ��ʡ��硢�衢Ǭ����������姬�ס��ݡ��ɡ��ȡ��á��ϡ��ء�ԫ����ܪ������̹����������������ܢ�������Ρ��롢�桢����Ҽ���塢�����⡢��˾���ӡ�����ﲡ��ڡ��Ρ��㡢ﶡ��̡����������ǡ��١�ʭ���¡��ס��š�����ͭ���ɡ��ѡ����͡��֡��桢�ա������塢�ԡ������롢�ࡢѸ���ơ� �������г�����Щ���У��еĵ�������ıʻ������һЩ���ò��ף��硰�ܡ�������������ΪӦ�úϲ������չ�ʹ��ϰ�ߡ����ⲿ��ֻ�����������������Ȼ����������ң����ﻹ������ҲҪ�����뵽�����⣺һ�ǡ��ܡ����������Ϊ���ò��ײ����֣���ô�ͱ����ڲ�ֹ����¼Ӹ�ע����Ҫע���м������ò���������������������Ϊһ���ʻ��϶����ȡ�룬������Ҹ�ȡ���룬�����ڷ�ɢ���롣���ּ��Ĵ����ͱ��뷽��һ����ϵͳ�Եģ�ʹ����һ������İ취֮���Ŷ���������һ�������⣬����ô�����ȶ�Ҫ�����ﻮ�����������������ijЩ��Զ����ĵ����ʻ���Ϊһ�����ף��Ժ��ֵIJ�֡������ķ��࣬�Լ����Ķ��壬��������µ����⡣����������һ��ϵͳ�Ե����⣬�����ϵ��Ӱ�춼Ҫ�������и�������Ҫ�չ�����ʶ��ϰ�ߣ��ֲ�Ӧ���������������������Ϊ�������ֵĹ����������Եģ�û�����ԾͲ����������֣������ֵķ�չ�������Եģ�����ԭ�е����ԾͲ���ǰ������ �塢�����ij�˵ �����������壬�ڲ��������嵥֮��Ȼ���������û�������IJ����������Ǻ���Ӧ�������������ֵĻ�����Ԫ�������������ǵ�ѧ���粢û�У�Ҳ��������Ԥ�ȸ���ЩͻȻ�����IJ����趨���ơ���Щ������Ȼ�����ڳ�˵����Ҫ���Ǹ��������������˽�˻�˵��Щ�����ǡ����������ġ�������Ϊ���������κ������ﲻ���������ƣ���������ģ�������һ��������������Ȼ��Ÿ���ȡ���������������������ڽ̣�����ѧ����ʶ�����������档 �����嵥�е���һЩ�����dz��֣������Dz��ף������ֳɵ����ƣ���Ȼ����Ҫ�ٸ������������µ�һЩ�������е����ֵ����벿�֣������������ǵ��������٣�û�С��ʸ����ף����硰�顢 �� �� �����������е���Ϊ��������һЩ�µıʻ��ṹ�飬�����Ƿ��ϲ��������еĹ涨�����ԣ����硰 �����������е���Ϊ��������һЩ�µıʻ��ṹ�飬�����Ƿ��ϲ��������еĹ涨�����ԣ����硰 �� �� ������������Щ���������Ƕ���Ҫ������ͳһ������ ������������Щ���������Ƕ���Ҫ������ͳһ������ ��θ���Щ����������������Ϊ��ȷ�������嵥֮���Բ�������Щ������صĺ��֣�������֮��ʹ��Ƶ����ߵ���Ϊ���ݣ����ݸò������ڵIJ�λ����������������������Ҫ�Ͻ��������ظ������硰����ͷ������˵�ɡ��ġ���������ͷ��������˵�ǡ�����������˵������������������
�ο����� ��1���´��ڵȣ����������������ԭ��̽�֡����ء�������Ϣͨ���������ļ���108ҳ�� ��2�������ģ����������뷨�����ٱ����װ���Ӵ���95���İ����С������ڡ�������Ϣ��1996���3�ڡ� ��3���������������α����ԭ����ʵ��������������Ϣ�����������ֻ����ļ����ڶ�������23ҳ��1983�ꡣ ��4������ɣ����ִ����ֵIJ����з֡����ء���������Ӧ�á���1995���3�ڡ� ��5��Ǯ��ֺ����Ҳ̸���ֲ����ͺ����ָ������ء���������Ϣ����1995���5�ڡ� ��6��Ǯ��ֺ����Ҳ̸���ֲ����ͺ����ָ������ء���������Ϣ����1995���5�ڡ� ��7�����������ִ����ֲ��������Ĺ淶�������ء���������Ӧ�á���1995���3�ڡ� ��8���°��ģ������ֱ����������ʵ������12-13ҳ��ѧ�ֳ����磬1986��8�¡� �� | 


