�� �ۺ��ֲ�ֵ�ϵͳ�� ������������ƪ��������������������λ����������ġ����ԭ����ָ�����ֵIJ�ֱ���ϵͳ�����˵�������ľͺ��ֲ�ֵ�ϵͳ���������� ���ֲ��֮���Ա����Ľ���Ϊ��������Ϊ�������ĸ�ϵͳ����һ��ϵͳν�¾ɺ���ϵͳ��������Ϊ�����Ľ�û����ʶ���ִ�����ϵͳ��Ŵ�����ϵͳ�IJ�ͬ����������Ϊ������Dz�������ʵ�������ǹŴ�����ϵͳ�Ļ�����Ԫ���������ִ�����ϵͳ���м��Ρ����ִ�����ϵͳ�в�������������ڹ�ȥ�ĺ���ϵͳ�Ķ��壬�ͻ�ʹ��ֱ�����ѡ��ڶ���ϵͳ�Ǻ��ֱ���ϵͳ����������ϵͳû����ʶ���ͻ���Ӹ��������塣������Ǹ�����ȷ����ֵĽ��ޡ�����û�ж��壬���û�˽��ޣ���Ȼ��û������ˡ���ֺ���Ϊ������Ŀ���DZ��ƺ��ֱ��룬��ˣ��������붨����������Ҫ���з��ࣻ�����Ҫӳ��Ϊ���롣���ң������������Ҫ�벿�������������������������ϵͳ���͵��ڶԺ��ֵIJ�ֵ�Ŀ�ĺ�����û����ʶ����Ȼȱ����ʶ�����Ѿͺ�����֡�������ϵͳ�Ǻ��ֲ�ֵ�Ψһ��ϵͳ��������ͳһʹ�á�ͳһ���������֣���ô���Ѻ��ֲ��Ϊ����Ҳ�������Ψһ�ԡ�����Ӳ���ϵͳ���ҳ���ֹ��ɺ������˲�ֹ��ɺ�������Լ�����Ķ����ͷ��࣬����ʵ��Ψһ�ԡ����ĸ�ϵͳ�Ǻ��ֲ�ֵ���֪ϵͳ�����ǽ�������ѧ����������������ѧ��ѧ�Ĺؼ��������Ϊ�˱��룬����ѧ�ı����������֪����ˣ���������������¸����ֵĿɽ����ԣ���ֵĿ������ʣ���ֵ���Ϣ����ʡ�����������������ǵ�ͳ�����ݣ��Ϳ�����һ�����뷽�������ӡ� �������α������й���Ϊ��������뺺�ֵ�һ��ΰ�٣���Ϊ��Ҫ������������һ����������ֱ�����������ء�������ѧ���˺�����������֮��ʵ��Ҳ����֪���˺������ε����ԡ� ���е���������Ҫ��ֺ��֣��еİѺ��ֲ��Ϊ�ʻ����еİѺ��ֲ��Ϊ�ָ����еİѺ��ֲ��Ϊ��������ֵ�Ŀ���ǰѺ��ֵ�������Ϣ��ת��Ϊ���̷��š����ü����Ѻ��ִ��ڼ�������ʾ����Ļ�ϣ������Ͻ������룩��Ϊʲô�����ַ�����ʾ����Ļ���أ�ԭ�����ڼ���������Ѿ�������һ���涨���ַ�������������֣���ʹ������ֿ����棬��ͨ����������������Ƴ����ġ�����ʹ���߽��Ӿ�����������ת��Ϊ�����ϵķ��ţ���ͨ����ָ������ʹ�������ĺ���������Ļ�ϡ�����DZ��뷽����Ŀ�ġ� Ҫ�뼸ʮ�������������еĺ��֣���Ӧ�ý����ּ��Բ�֣�ÿ�����ֶ�ʹ��1~4����������ʾ������26��Ӣ����ĸ������������ϣ�����ʹ��ʮ�����ļ�����ȫ�����֡� ���������ձ�ʹ�õĹ�������ֿ⣨����6763�����֣����ֿ����ÿһ�������ַ�������һ������ͳһ�涨�Ĵ��룬��Ϊ���롣���뷽������ߵĹ����������ƶ�һ���Ĺ����ٸ�����Щ����ֺ��ֲ�������������Σ���������һ���Ĵ��롣��Ϊ��ÿ�����ּ�Ȼ�����������������ȻҲ���ܵõ����������ˡ���Щ�����Ϊ���ֵ����롣�ַ����е�ÿ�����֣������������뷽��������ˡ�ʹ�õ��Դ�����ֵĹ������ɳ��������Ա������Ӧ�ij�������ת��Ϊ���롣ʹ����ֻҪ�ڼ������������룬���־�����ʾ����Ļ�ϡ�����������������뷨�Ĺ����� ���ֵ�ʹ�û���Ҫһ������ϵͳ����ȥ����ʹ��CCDOS����������ʹ���Ӵ�98����WINDOWS�����������IJ���ϵͳ������ij�����������ϵͳ�ҽӲ��ܹ�������ȥ��CCDOSϵͳ��Ҫ����������Լ��ҽӡ����ڵ��Ӵ�98ȴ�������뷨����������������߲�����Ҫ�������������ֱ�������뷨�����������ɹ����ļ����������ˡ� �����������ṩ��������ѧϰ�õġ��û��Ĺؼ������㣺һ���Dz�������ѧϰ�������Dz��DZ���ʹ�á�����úã������֧�֣���ò��þͻ��ì�ܣ��ͻ�������������˵��һ������ѧ�����ã����ò���ѧ�� �������ʹһ�����뷽���Ⱥ�ѧ�ֺ����أ��ؼ�����Ʒ����Ŀ�ѧ�ԡ������˲�֪��ijЩ��֮����ʹ�˾������ѣ�������Ϊ���˽���Щ�����ϵͳ�ԣ����˽�����ϵͳ�����ڽṹ���������������һ��Ե�ʡ����ֱ�������ѣ��ؼ����ں��ֵIJ�֡���ν��������һ����ָΪ��ֶ��о���֣�����Ϊ�������о���֣�Ϊ������о����룬��֪�����ֱ����У����������壬���루���룩�ǿ��壬��֪�����о��������εĿ۹��ɣ��Ͳ��ܸ�ú��ֵIJ�֡�����������������о����룬���о����ò�֡� �������ʷ���������α���IJ�����Ӧ��˵������ʼ������Ϊ��ʹ�����ܹ�������������������У������540�����ס����ף����Ǻ������ε�һ���֡�����һ�������Σ����������֣�����������������Ⱥӡ���Ȼ��540�����ױ����ļ���Ҳ���Ǹ����⣬�����ͽ���Щ�����Է��ࡣ��Ȼ���ַ���ķ�����ʮ�ֿ�ѧ��������û���κ���ƾ��Ҫ����������в鵽ij���֣���ȻҪ����ö��ˡ� �����������ú��ֵIJ��������������������������ڵĺ������α������ò������α�Ϊ����Ѻ������������ͬ���ĵ���������Ϣ���ݵĽǶ����������ֵĺ������η�ӳ���ֵ�������Ϣ����������ܹ��Ѻ��ֲ��Ϊȫ�����������ܹ���ӳȫ�����ֵ�������Ϣ����ʷ�����������������Ԫ�����ء���ԭ�����������ֵ��м��Σ��Ա��ֺ��֣��õ����Ļ�����Ԫ����ʼ������������ʵ�������Ǻ���̫�Ѳ𡣶��������IJ�ǡ����ֱ��������������������ֺ�����ֵĻ�����Ԫ�����������ˡ� ��������ʮ��������һֱ�о����ֱ��룬���з��ֺ����Ѳ��ԭ������Ϊ���Dz����⺺�ֲ�ֵ�ϵͳ��֮�ʡ����ֵIJ��������4��ϵͳ���������ں� �� һ���Ž���ϵͳ�� �ҷ����е���̸���ֲ�֣����������ġ�����Ϊ�ģ�����Ϊ�֡�֮˵���Ѷ�����������������������쾭����ؾ����ֳɵIJ����������Dz�֪������˵�Ķ��壬�ǹŴ�����ϵͳ�Ļ�����Ԫ���Dz��������������õġ��Աʻ�ϵͳȡ���˾ɺ��ֵĻ����ߺ���ϵͳ������ֻ��������εġ��ɡ����塪�����塱���ɵĺ���ϵͳ�ˡ������ڹŴ����������㡱�ȶ��Ƕ��塣�������Щ�ֶ����ɺ��ֵIJ�������ֵ����Ѿʹ��ˡ���Ϊ������Щ���У����ߡ���������dz��֣�һ�����������У��ͺ����������֡�һ�����������������ֻ����Ǿ�˵����ȥ�ˡ����ԣ��ùŴ��ĺ���ϵͳ���ֽ��ִ�����Ϊ�������в�ͨ���ִ��ĺ���ϵͳ���ɡ��ʻ����������������֡����ɵ�������ε�ϵͳ���뿴�±ߵġ��Ž�����ϵ�Ƚ�ʾ��ͼ����������ѧ������ϵ������Ҳ�dz��֣�����������ɶ���ƴ�����ġ��ִ�����ϵͳ���ɱʻ������������ֹ��ɵģ�һ���ֱʻ��dz���Ҳ�Dz��������硰һ���ҡ���һ���ֱʻ��Dz������dz��֣����硰ح دؼ�S���]���ȣ���һ���ֲ������DZʻ�Ҳ���dz��֣����硰�ڡ�⺡��֡������ݡ��Ρ��ꡱ�ȡ����ϵͳ����ѧϵͳ���ྶͥ���������ʶ���������ѧϵͳ����ֺ��֣��Ͳ��������� 
�� �������ֱ���Ľṹϵͳ ����Ҫ��ɴ��룬�ͱ����ֺ���Ϊ���������������������г�һ�Ų����嵥�����������嵥�еIJ������࣬Ȼ��������ӳ��Ϊ���롣�������IJ�����뷽��������ˣ�ʣ�������¾��Ǹ�ÿ�����ֱ���룬�γ�һ�����к��ֵĴ������������ó����Ϳ������������ר�ұ�����뷨�ڼ���������뺺�֡����ڵ�windows98����ϵͳ���С����뷨�����������������ֱ���������뷨�����������ֻҪ����������Ͳ���Ҫ����������ר���������뷨�����ˡ� ���ֱ��뷽���Ļ�����Ԫ�Dz����������Dz�ֺ��ֶ��õ��ġ����ǣ�û�в����Ķ��壬��û�а취��ֺ��֡����ԣ���Ҫ��ֺ��֣�����Ҫ���������塣80��������ָĸ�ίԱ���������һ�β���Ƶ��ͳ�ƣ��Ѿ�����һ�ζ��壬��˼�ǣ��������ڱʻ���С�ڻ���ڳ��֡��������ʵ���Ǻܲ���ѧ�ġ�����ѧ�IJ������壬��Ȼ����������ѧ�IJ������� ����������ǻ��������ں����еı߽硣Ȼ���������ڡ�С�ڡ����ڡ���Щ���������ں�������ȷ�ػ��������ı߽磬��Ϊ��û�н������ֲ����ı�������������ȻҲ������ȷ��ֺ��֡����ԣ�����û����ȷ�Ķ��壬���һ��ָ���ĺ����ַ����ĺ���Ϊ��������Ȼ�������ء� ����Ϊ��ֻ������ȷ��ʶ�������������������ȷ���������塣 ������������Ǵӻ�еѧ�����õġ��������� ��һ�� �����м��Σ������������������ٵ�������� ������ ������Զ����ģ� ������ ���ǿɵ�������ģ� ���ģ� ���������𡪡�ƴ��Ӧ���ǿ���ģ� ���壩 �����������������������Եĸ��š��� 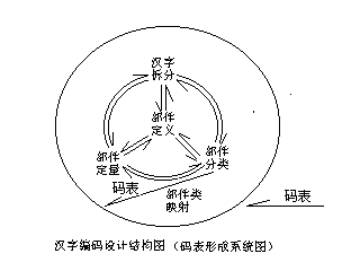 ���������ڱʻ���С�ڻ���ڳ��֡�����������壬����Ӳ��еѧ�еĸ������֪���ֺ��ֲ������еѧ�еIJ����IJ�ͬ���ڻ�еѧ�У�����������������ǽ�Ȼ�ֿ��ġ��������У���һ���ҡ��DZʻ������Dz��������dz��֣�����˵��������ְ�������ڡ��ˡ��Ⱥܶ���֣��֡����桱�����������Ѿ��������ͼʾ��ָ����Щ��ͬ�ĵط�������Ͳ������ˡ�ͬ��������������Զ������ɵ������뿪������˼����ˣ���ȷ�IJ�������Ӧ���ǣ������Ǻ�������Զ����ġ��ɷ���ıʻ��ṹ�������ʻ��� ���������ڱʻ���С�ڻ���ڳ��֡�����������壬����Ӳ��еѧ�еĸ������֪���ֺ��ֲ������еѧ�еIJ����IJ�ͬ���ڻ�еѧ�У�����������������ǽ�Ȼ�ֿ��ġ��������У���һ���ҡ��DZʻ������Dz��������dz��֣�����˵��������ְ�������ڡ��ˡ��Ⱥܶ���֣��֡����桱�����������Ѿ��������ͼʾ��ָ����Щ��ͬ�ĵط�������Ͳ������ˡ�ͬ��������������Զ������ɵ������뿪������˼����ˣ���ȷ�IJ�������Ӧ���ǣ������Ǻ�������Զ����ġ��ɷ���ıʻ��ṹ�������ʻ���
�����������壬�Ϳ��Բ�ֺ���Ϊ�����ˡ�һ���ַ�����ֺͻ�õ�һ�Ų����嵥��Ҳ����˵�������ܹ������ˡ��κ�һ����ѧ����Ʒ������ӳ�������˵�����Ⱦ��Ǹ�ʹ�õĻ�����Ԫ���Զ�������Ƶı��뷽���Ļ�����Ԫ�Dz�������ô����ѧ�ı��뷽�����Dz����Ķ��Զ����������Ķ�����Ƕ��ԣ����ݶ��Բ����IJ����嵥�����Ƕ�������������ʹ�������˹̶������������ǣ�������ô�ࣨ���ٸ����IJ���������һ��һ�����������Ӧ��ӳ�䣩������Ҫ�ֳɼ�ʮ���࣬�Ա���ӳ��ɴ��롣���ݱ����о��������Ķ���������֡����������ཨ���л�����ϵ������һ�����Լ��ϵͳ������һ�����Ƶĺ��ֱ��뷽��������ҳ��ͼ�� �������壬�����䡰��Զ����ԡ������������������������䡰�ɷ����ԡ�����������ֺ��֣��䡰�ʻ��ṹ�������������������࣬���ɷ���ӳ���ÿ�����ֵĴ��룬�Ƴ�һ�������ĺ����ַ������������ÿ�����ֶ�����һ��������ܱ���������˺��ֱ���ϵͳ�����ơ���������ϵͳû����ʶ�������Ƴ����Ƶı���ϵͳ��Ҳ�Ͳ�������ȷ��ʶ���ֵIJ�֡� �� �������ֲ�ֵ�Ψһ��ϵͳ ������ȫ��ͳһʹ�õ����֡����ֲ�ֳ��IJ�����ҲӦ����ȫ��ͳһʹ�õIJ��������ԣ�����Ҫ���ֵIJ�־߱�Ψһ�ԡ���νΨһ�ԣ�����Ҫ��ÿ�����ֵIJ�֣���ֻ����һ�ֲ�ֵķ�������Ӧ�еڶ��ֲ�Ȼ���������Ǻ��ֵ��м��Σ��ڲ���б�Ȼ���������ԡ���ˣ����˲����Ķ���Ͷ���֮�⣬�������ƶ���ֵ�ԭ���������ֹ�����ԡ�Ȼ������ֵ�ԭ���������ƾ�ն����ģ������������оݣ������붨�塢���������л�����ϵ������ܹ�����һ�����ֲ�ֵ�Ψһ��ϵͳ������ͼ�� 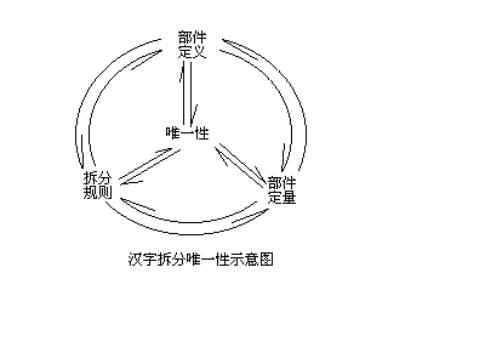
�����о��˺ܶ����α��뷽����������Щ��������ȡ�뵱���˲�֡���ʵ�������ȡ����������ͬ�ĸ��ȡ����ָ��һ�����������ȡ������Ҫ�IJ����Ա����롣���������ָ��ΰ�һ�����ֲ��Ϊ�����������ֲ��ܱ�������ԭ����� �����ͼʾ�������ж�����ܲ�֣��ܲ�ֲ��ܵõ������嵥�����������������������˼��Ȼ�������ס����ǣ�û�в�ֹ������Ͳ��ܶ�������Ϊ���������ɱʻ����ɵġ����嵥�У��еIJ����ɲ�ɲ���û����ȷ�IJ�ֹ������������ѣ�������˵��ֻ���ڹ����ж������������𡱣��嵥����ȷ��������ֹ���Ҳ�������ֲ����ı������ԣ����ԣ����벿�����壬ͬ�������Ų��ɷָ����ϵ�� �� �ġ����ֲ�ֵ���֪ϵͳ �����ֲ��Ϊ�������������֪������������ȫ�µĸ�� ��һ����ֵĿ��������������ʵķ�����������ʣ� ����ֵġ������ĺ��֣����ܴ���������ȫ�����ֵ�������Ϣ�����ǣ�����ֵ�Ȼ�Dz����ܵġ���Ϊ��������ֻ��26 ������ļ���Ҳ������Ϊ����10�����ּ�Ϊ36������ļ���������ֺ���Ϊ���������ܹ�ʹ�����������Ϣ�ı�Ϊ����������Ϣ��ӳ��Ϊ������������ü�����������У�����ʹ��ǧ�����ֺ����Ĵ���õ�������������롣�����˵���Ѻ��ֲ��Ϊ�����������ú���������������Ϣ���������ʣ��Ա�����֪���Ͳ���Ҫ����Ӳ���ˡ�һ�������Σ��ͻ���ϵ�������Ĵ��롣����Dz�ֵ�Ŀ�ġ� ����ÿ�����ֶ���Ϊ�ʻ������ܵ�ȡ������ƣ��������������ʡ����е��ֱʻ���Xʮ����ÿ���������������ܶ�Σ���ˣ�������ʹ�á����ԣ���Ҫ�����ֲ��Ϊ���������������٣�һ�۾Ϳɿ��������ʻ��Ͳ���һ�ۿ�����Ϊ�����Ŀ������ʲ���Ӱ����֪��Ҳ��Ӱ�����룬���Dz�����ġ����ԣ����б����������������ֵĹ��ɣ�ÿ�������ȡ�ĸ����롣��ֵ�Ŀ����Ϊ�����룬���벻�����ˣ����������Ҳû���ˡ�һ���ֵ������������ʵ�����Ч�������ֻ����������룬���������Բ�������Կ��Է�ӳȫ��������Ϣ�� ��������ֵ���Ϣ����� �������Ժ��ֵ�����������Ϣ�����Ϊ����������Ϣ�����б����ķ��������ԣ�������Ľ����ȫ��������Ϣ���ܷ��أ���ʵ������Ϣ��ġ����罫���ա��ֲ�Ϊ���ա������ڡ��ᡱ�ĸ���������ô����ֺ�����룬���ĸ�������������Ȼ���ĸ�����������ԭԭ����һ�㶼���ٵ�����ƴ�ɡ��ա��֡���ͽ�����Ϣ����ġ� ���������ĸ��ĺ��֣�Ϊ������Ч�ʣ�ÿ����ֻ�ܲ��ã�ȡ�룩�ĸ����룬�����࣬ȡ���٣�������ľͽ���������Ϣ��ġ��������Ļ�Ӱ�������е���֪��һ���ַ����У������IJ����������������̣���Ϊ������Ϣ����ʡ�������֮���Բ���ȡ��������Ϊ������Ϣ��Ĺ��ࡣ �����Ϊ�����𣬲������ô�������Ϣ����٣��������ʻ���Ӱ�졣��������ӵ�еIJ����������ȣ�ȡ���ֱ������ƣ���ָ�����ַ����в��ܲ�����ijЩ�ֵ�������Ϣ��ġ���ˣ�����Ҫ�����Ŀ������ʺ����ٵ���Ϣ����ʡ�ͬʱ�Ѳ�ֵĿɽ�������������Ҫ��λ�á����ԣ��������ʵ��IJ�����λ����ȷ�������Ĵ�С������Ȼ�����ݱ����о��������Ĵ����ǿ۵ģ����������������۶�λ�ġ� ��������ֵĿɽ����� ��ֺ��֣�����Ҫ�������ǵ������Ƿ�������ܣ���Ϊ��ֵĿɽ����ԡ���ֵĿɽ�����ǿ��һ�۾Ϳɿ�������ֲ����ı߽���������м�����������֮�� ���硰�ɡ��IJ����������ʽ�� ������ һ���ڡ��| һ��ح���S��һ���| ���ϵ����ַ�������һ������Ϊʹ���ߵ����������ܣ���Ȼ�ǵ�һ�֡���Ϊ�������ǰ���ǡ������ֲ��Ϊ�����������ɡ��ֵ������������������롰�ڡ���һ�۾Ϳɿ�������ԭ��������֮�������Եļ�϶�����ԣ�����пɽ����Ե��ǰ���϶��֡��е�����Ϊ��Ӧ��Ҫ��ÿһ����ֺ���Ϊ����ʱ�����뺺����д�ʻ�һ�¡�����������Ӧ�����������ǣ��ⲻӦ����Ϊ�Ⱦ���������ͺñȰ�һЩ�����װ�ɲ���������װ�������������ܶ�����װ�ò���������װ�������ġ��������������װ����ȻҪ�ǰ����˳����ʱ�������ijЩ�����в���ij�����������ʹ��������װ�ϣ����������ֻ�ֿܷ���װ��˵���ֵIJ���Ӧ����˳��֣������ͻ�ʹ���ɡ��ֵIJ�֣����������ĵڶ�����ʽ�����ǣ���ڶ�����ʽȴ������ʹ���������ϵĽ��ܡ�����ѡ�����˳��֡���Ϊ�Ⱦ���������ô�ͻ��γ������ϵĵ���ʽ����ȫ�����Ϊ�ʻ��������ǽ����ֲ��Ϊ�����ˡ� �������˽����ڡ� �� Ҳ��Ϊ����������Ϊ��������ġ� ����û�г�˵�����������٣����Dz�������ˡ���ͺñȰѡ�����Ҳ��Ϊ����һ����Ĩɱ�˼�϶��������������϶���ܲ�ֺ���Ϊ�����ģ�û���˼�϶�����־Ͳ��ܲ���ˡ��Ҳ����Ը����������ǣ������������ڲ�ֹ�����������֡� ����û�г�˵�����������٣����Dz�������ˡ���ͺñȰѡ�����Ҳ��Ϊ����һ����Ĩɱ�˼�϶��������������϶���ܲ�ֺ���Ϊ�����ģ�û���˼�϶�����־Ͳ��ܲ���ˡ��Ҳ����Ը����������ǣ������������ڲ�ֹ�����������֡� ������ӱȽϵĵ�һ�ַ������ɽ����ԡ�������Ҫ��ֵĺ��ּ������ĺ��֣��ֱ�����ͳ�ƣ��Ϳɵó����İٷֱȡ� �ɽ����Ա����и�ǰ�ᣬ���Dz����ж��塣�����Ѿ��������ᵽ�������Ǻ�������Զ������ɷ���ıʻ��ṹ�������ʻ��������ͰѲ������������ͣ��ʻ��ṹ�顢�����ʻ����������������ԣ���Զ����ԡ��ɷ����ԡ�������Ϊ���ü�϶���õ��ģ�������ˡ��������Dz�����������ʲô�����ס��������塱��������ν�����ƣ����������Լ������Ե����ơ���Ϊ�������ס����塱������û�п�ѧ�Ķ�������ʵҲ�����������������������ڹŴ��ĺ�����ϵ�����塪�����壩���������ִ��ĺ�����ϵ���ʻ����������������֣������ԣ����ִ������У�����������������һĿ��Ȼ���������������ڡ������ִ�������ϵ���۹������������͡��ᡱ��������Զ����ġ���ͬ�ıʻ��ṹ�飬�����Եļ�϶����ˣ���Ϊ���������Ǻ�����Ϊ���������������ܵģ��෴�أ����������Ϊһ���������ͻ�ģ�����������ԣ�����Ϊ�������������ܡ����ֲ�ֵĿɽ�����Խǿ��������֪�ij̶�Խ�ߣ���־�Խ���ס�  ���ֲ�ֵĿ������ʺͺ��ֲ�ֵ���Ϣ����ʣ�����ֱ��Ӱ��������Ϣ����֪��һ���ֲ��Ϊ�ĸ�����������ȫ������������Ϣ��������ȫ�Ŀ����ԣ���ˣ�ѧϰ���������ܡ���ν��ȫ�Ŀ����ԣ���ָ��������ĸ���������������װΪԭ�����֡������ĸ��������֣�����ֻȡ���ĸ��룬��һ����������Ϣ����ˣ��Ͳ�������ƴ��ԭ�������Σ���ɽ����Ծ��ܵ�Ӱ�죬Ҳ��Ӱ����֪��������˵�������ĸ��������֣����ܰ���ȫ��������Ϣ�������������ܲ��ˣ�Ҳͬ��Ӱ��ɽ����ԣ�Ҳ�ͻ�Ӱ����֪����ߵĿ������ʣ���͵���Ϣ����ʣ��������Ŀɽ����ԡ�����ͼ�� ���ֲ�ֵĿ������ʺͺ��ֲ�ֵ���Ϣ����ʣ�����ֱ��Ӱ��������Ϣ����֪��һ���ֲ��Ϊ�ĸ�����������ȫ������������Ϣ��������ȫ�Ŀ����ԣ���ˣ�ѧϰ���������ܡ���ν��ȫ�Ŀ����ԣ���ָ��������ĸ���������������װΪԭ�����֡������ĸ��������֣�����ֻȡ���ĸ��룬��һ����������Ϣ����ˣ��Ͳ�������ƴ��ԭ�������Σ���ɽ����Ծ��ܵ�Ӱ�죬Ҳ��Ӱ����֪��������˵�������ĸ��������֣����ܰ���ȫ��������Ϣ�������������ܲ��ˣ�Ҳͬ��Ӱ��ɽ����ԣ�Ҳ�ͻ�Ӱ����֪����ߵĿ������ʣ���͵���Ϣ����ʣ��������Ŀɽ����ԡ�����ͼ��
���뷽�������ӣ����Ծ������㣺��ֵĿɽ����ԡ���ֵ���Ϣ����ʡ���ֵĿ������ʽ��бȽϡ���������ϵͳȱ����ʶ����ֵĺû�����֪���� ���ϵͳʵ�ʾ��Ǻ��ֲ�����ӵļ��ϵͳ���κ����뷽���������������ϵͳ���м�⡢�Ƚϡ� �� ������ �Ž���ϵͳ˵�����á����塢���ס���������ͷ���ף�������Ź�����������ã�������������Ϊ�������ϵͳ�У�û�в����� ���ֱ���Ľṹϵͳ˵���������ⲿ���������Ҫ�Լ����֡�����������Ĺ�ϵ��������ֺ���Ϊ������ ���ֲ�ֵ�Ψһ��ϵͳ˵������ֹ����ڲ�����붨���������������ϵ������ֹ�����������õģ������������嵥����ɳ����ģ����������ν�ѧ��ͳһ�ģ����Ժ��ֵIJ�ֱ�����Ψһ�ġ� ���ֲ�ֵ���֪ϵͳ˵����ֻ��������֪�IJ�ַ������������ѧ�ģ�����Ϊȫ��������ܡ����������п�ͳ���ԣ���ˣ��Ϳ������˽��к��ֱ��뷽�����ӵıȽϡ� �����֪��������˵���ĸ�ϵͳ��������ѧ�ذѺ��ֲ��Ϊ������ ��ν���ֱ��룬���������壬�����ǿ��塣��ҪѰ����ν����ֲ��Ϊ��������ν������ֳ��ʺϱ��������������ɣ�Ҫ���������ֱ�ӵ�ת������������ת���ɴ���Ŀ�����ɡ���ˣ����Ĺ���Ӧ����������ѧ�о��ķ��롣����������Щ�о������ε��о��������Dz����������������������������壬�Ѿ����Ͼ���ϵ���ˡ����ҹ��������о�����ǧ������һֱ�����壨ѵڬѧ��������������ѧ�����תת������û��ר�ŵ������о������ԣ���������ѧ�ң��ں��ֲ����ǰ�Ե������ߡ��ټ��Ͻ�һ�����������������ֱ���Ϊ�������֣��ڶ������ѧ�һ�������ƴ������ȡ����֮����ô����˭Ը�⻨�������о��������ġ��������ŵ������أ�����һЩ��������Ϊ�����ֱ����Ǻ��ֵļ����� ������Ȼ�ǡ�������������ʲô�о��ļ�ֵ�أ����ԣ����Ǿ���Ϊ��Զ����������ˡ���λ����ѧ������˵����ʲô�Dz�����֣��Ѻ��ֲ��Ϊ��������Ϊ������֡��� �����е�����̶ȣ�������������Ϊ����������伫��������ԭ���ĵ�Ȼ����ϸ���������Ҫ�����ˡ� һ�����ֱ��룬��һ����Ʒ�����һ����ѧ����Ʒ��������Ⱦ�Ӧ�ý���һ��ϵͳ�����ۡ�������������������Ʒ�����ȴ�䵭�ڻ������۵Ľ��衣����ǡ����뱼�ڡ�������������ʮ������һֱ�����ں��ֱ���Ļ��������о������ɡ����ֱ������ѧ��������߾��û�����Ҫ�˽�ĵط������߶Դ����������������뱾����ϵ�� ע �� �����������Ӻܶ࣬��������ɵġ��ִ����ֲ����з֡��ء���������Ӧ�á�1995��3�£� �ڹ��ڲ����������������˵��ڡ�ղ��Ȩ���������ֱ������ѧ����114ҳ���й����г����磬1997��11�¡� �ۼ�Ǯ��ֺ��Ҳ̸���ֲ����뺺���ָ������ء���������Ϣ��1995��10�µ�5�ڡ� �ܼ����Բ�����˵�Ľ��顷���ء����������•ר�ⱨ����1998��4��27��D5�档 �ݼ��˵��ڡ�����ѧ�ؿ������֡�����С����ء������Ļ���1999���4�ڡ� ���������ƶ������ֲ����淶�����������⡷���ء����������•ר�ⱨ����1988��4��27��D1�档 �� �� �� | 


