�� ���ֲ���ϵͳ�о� �� ���������� �� �����������Ӧ�ã�������׳���ĺ��ֱ��벨��,����ר��Ͷ���˺��ֱ������ơ���һ�ȳ��ı�Ȼ����Ҫ����Ǻ������뷽����һ���С����칦�ܡ�Ӥ���������ء�������칦�ܣ������ų���ƴ������������IJ��������ԣ��ܹ�ä�� ���������룬һ��ʼ���ų������������ĸ��š����ǿ��ܲ�δ���죬ʱ�����գ���������Ϊ�������Ĺؼ�������������ٶȺͼ��������ʡ����������ʶ�����������ڱ������������˶�ʮ�꣬�������ڻ��ڶ�Ȧ�ӡ����ں��ֱ���������ٶ����⣬��ϵ����Ա�ļ��ܺ������̶ȣ������ڵ�ʮ���ڣ�רд�������������������й�������¸���Է������е��ɻ� ���ż��������Ӧ�õ�չ�������ֱ��뷽���������࣬���뷽�����о���δ�õ�����ѧ���㹻�����ӣ��е���������Ϊ��������ֱ��롱�Ǻ��ֵ�һ�����ѣ���������Ϣ��Ĵ������۵�����������Ϊ�����������в�ֵ����ѣ���������ˡ���������ļ����������ǣ���������ijЩ�˵IJ�����ڮ�ٶ���ʧ������������졣�����ֱ��롱��ʾ������������һ��ǰ��δ�е�ΰ���������ǧ��Ӧ�õ����������ڳ���һ�δ�ת�ۡ������ִ�ƴ��Ӧ�ã���Ϊ���Ӧ�á���Ԥʾһ�ٶ������й���Ϊ֮�ܶ��ĸ��ֺ����ִ���������Ŭ������ʵ�ֺ������� �����ֱ��롱�ĸ��������ڡ��𡱡��е��������ΪֻҪ�ҵ����ƶ�һ���IJ�ֹ��Ϳ���һ���ӽ����������ѣ���ʵ�ϲ������ס�����������ǰ����һ�º��Ѵ���ǽ��������ϵͳ���о���˭���������������⡣�����ֱ��롱��Ҫ����IJ������Dz�֣����в����Ķ����ͷ��ࡣ ����������ļ���о����ڷ��֡����ֱ��뷢չ�켣���Ļ����ϣ��ַ����ˡ����ֱ��롱��һ���Զ����������࣬�Է�����Լ��֣��Բ�־���������ѭ���ṹ��������Dz����Ķ��壨��˷����ˡ��������α��뷽����ͻ�ƺͽṹ�����������壬������֣�����Զ���ܽ����ᡣѧ���������С����Ҷ��в����Ķ��塱֮˵����˵ȴ�Dz������岻��֪�ķ��档���ĵ�������������������ƣ��Ѷ��彨���ڸ��ݱ������Ҫ��Ŀۻ����ϡ��Բ����Ķ��������������嵥�����嵥�й��ɳ���ֹ��Ӷ������˲�ֵ������� ���ĵ�ʮһ�ڣ����ݲ����������������ԣ����嵥�е�ÿ�������Ϸ��ԡ�����������֤���������������ۡ���Ϊ���˵������������ġ�ȷ�������嵥�Ǽ�����Ҫ�����Ͻ����о������뼯˼���棬�������ã������ݺ���������嵥��ʹ�����IJ�����������ѡȡ���嵥��ֻ��352�����������ĸĻ��648����������40%ǿ������������嵥�ķ����õ���ʶ����Ȼ����ֻ�ǹ���������ֿ�ģ����������ֵĺ������νṹ���ɣ����Ѿ��������š���ˣ����ܽ���ַ����е��ַ���Ҫ������࣬δ֪�IJ�����Ҫ��Щ���������ǵķֽ⡢�����Լ����룬��û�б�Ҫ����������ˡ�������ô˵�����ֵ�����Ԫ�أ���������ĸ���ҵ��ˡ�һ�׳���ĺ�����ĸϵͳ����������ͳһ���ֱ��룬�߳������ս��ʱ�����������Ų���Ϊ�����������Сѧ�Ļ�������������Ҳ�����Ϊ����ͳһ�Ĺ������緢����ҹ�������Ҳ����Ϊû��ͳһ��������������� ���뷽������ħ�����������ܸ��ӣ�˵������ʵ�ܼ�����������˵�ġ����롱���Ƕ��ʵġ����롱��רָ�Ѻ��֡���Ϊ���롱����˼�������뷽�����к�����������棺��۵���ָ������������Ʒ������۵�����ָӳ��ķ��������ĵ�ʮ���ڣ���д�۵ı��뷽���������оټ������뷽����˵�����벻�Ǽ��������ǡ��������ĵ�������������ܹ�ͳһ�����嵥��ͳһ����ϵͳ�����Dz�ͳһ��������룬���˻����Ը�����ͬ�ķ������ο����ڵIJ��������������������û��ͳһ���������ڵ����룬��ֻ˫ƴһ�֣�������ĸ���ŵIJ�ͬ���Ϳ��ж��ַ����� 1986�꣬ȫ�����к��ֱ������⣬�������Ҫָ���������ٶȡ��˺�ļ����ڣ����ʺ������̲��ϵؽ��и��ֺ��ֱ��������ٶȱ�������Щ����ɴٽ��˼����Ӧ�õ��ռ�������Ҳǿ���ˡ������ٶȾ������뷽�����ӡ��Ĵ���۵㡣Ϊ���������ٶȣ����������Լ�ҹ�������룬Ϊ���������ʣ���ϧ���ֹ淶���е������ƴ������ʿ⣬Խ��Խ�á���һ����������Ͷ��Ľ��ȴ����ԸΥ����ʵ˵����λ�����˺��ֱ��������뷽��������ͬ�ĸ�� ����������������ɵ����غ����һֱδ���йز��ź�ר�ҳ����ʶ�����ʹ���ֱ���ķ�������Ϊһ�֡�������������ר��Ȩ�����淶������Ӧ�ñ�������ר�������������������������Ľ�������֮Ϊ����Ȩ����ר�����ײ��ϳ��֣�ִ��������������������ά���������淶��������Ʒ���š�ר�������������������Сѧ����ϵͳ��Σ���Ļ�������ҵ������������������ġ������������¡�������Ⱦ�������˵��ǵ���ʵ�ǣ�ijЩ����ѧ�ı��뷽������������ͣ�������Ժ��ֲ�ֵIJ��淶�ܵ����ж�����ĺ��ɽ����ȴ����������뷨��������������֯�������������Ч���г�ռ�죬���ڽ�����������Ŀ��ã����ֵĹ��ɺ淶��������ʵ����������Ϣ������Ʋ���̫�á� �����Ӿ����ѵ���ͻ�������ü��������ġ���ʵ����ʮ������ȫ��������������ǧ�����뷽�������١���������ȥ�����ֵĹ��ɺ淶��Ҫ�����������õ�Ȼ���ˡ���ʵ�Ϻ��ֱ��뷽������ƣ����Ƿ��������Ǽ���������һ�ŷdz��Ͻ��ġ��������ƿ�ѧ�����ǵĹ������Ǽ����Ĵ����ٻ���š����ƻ���ȡ�����̡�������ר�ҹ��أ��ٸ��һ���������������·���������Ӧ������ء�ϵͳ���о�������Ƶ�ԭ��ԭ���ͷ�������������ϵͳ�Ļ���������ϵ����ʷ���Dz�ͣ���ھ���������ǰ���� �����DZ��Ʊ��뷽����Ψһ�Ļ������ϡ�����ء�ϵͳ���о����������������Զ������ǽ������ͳһ�Ĺؼ������ĺ����Ƕ��塣���ĶԲ������塢�����嵥�����뷽������������Ͳ�������������˳�����������Բ���ϵͳ���о���������ṩ��һ���о���ģʽ��ϣ���Դ���Ϊ��һ�����۵Ļ��������ż����Ӧ�õ����룬��ѧ�Ѿ�������ǧ�������й���Ҫ���Ԧ��ƥ��������������ʵ�ּ��������Ӧ�õ��ռ��������Ļ����Ǻ��ֱ������ơ����ֱ�����Ӧ�ÿ�ѧ������������ǣ�����Ҳ��Ӧ�������Ӧ�õĹؼ�ʱ�̣����䲻Ӧ������������רҵӦ���������ռ�Ӧ��ת����ʱ�̣����������е��о���ֻ������ֽ��̸����һ���ô�Ҳû�С� �����嵥�ij��������ƣ�Ԥʾ�ź��ֽ�����һ�κ���ʹ�÷����Ĵ��һ��һ��������ʹ�ñ��Ϊһ��һ�������ʹ�á������ֱ��롱ʹ����ʹ�÷����ˡ��ѱ䡱����Ρ��ѱ䡱��ʹ���������ߵġ������������ֵġ��ѱ䡱���Ǽ���Ӧ�õ���Ҫ��ɵġ�������ֻ����ô������������ȴ��Ҫ��ǧ��������֣�����֣���ʹ�ò�����˭��û�а취�� ����Ӧ�õı�������ԭ��ͺ���ԭ����������ʷ��ǰ��չ���Ļ�֪ʶ�ռ�����Ϣ�����ٶȵ�Ҫ��������ϢӦ�ù��ߵı����ɵĿ��ܡ�Ҫ��Ϳ��ܵĽ���㣬�������ֱ���ʱ�䡣�ɼ������ֱ���ʱ���Ѿ��������������в���������ԥ����ʧ������ �� һ�������о������弰�ع� �� ��ĩ��������ѧ���Ļ���ˮ��ӿ���ҹ���������һ�������ȹ����ߣ�������Ϊ������֮����ǿ������Ϊ��ҵ�����ҵ֮���Է�������Ϊ��ѧ��չ����ѧ֮���Է�չ����Ϊ�����ռ�������֮�����ռ�����Ϊ�����õ���ƴ�����֡����������Ľ�����ó����й�֮�����������Ϊ������һ���������ֵĽ��ۡ����ǾͰ����е�Թ������й�ں������ϡ�������ʶ�ϵ�ƫ��ʹ�����ڽ�һ�ٶ���������һ�����������ͼ��ƴ����ȥ���캺�֡����ƴ������ijɹ��ˣ�һ��ֱ�ӵĺ���ǣ�����ƴ������һ����������ä�����е��Ļ����ؾͶ����ˡ����顱����ͽ����Ļ��ϲ㡣 ���ڣ��е�����һ����̬����Ϊ����ΰ����˲��ã����ơ���ʮһ���ͽ��Ǻ��ֵ����͡�������һ�ֶ����ܶ�����ֺ��־ͷ��ˡ�����������������쾭���塣���˻���Ϊ���ף���Ȼ���Dz������ǾͲ���Ҫ�о������ˣ� ��Ҷ��Ѿ�֪������ʹ����ʹ��ƴ�����ֵ������ˣ�Ҳ�������ǵ����ֲ���ʮȫʮ����������ĸ�������ģ������������Լ������أ�������������ȫ��ӳ���ǵ�����ʵ�ʡ����ԣ�����Ҳ��һЩ����ѧ���ں����ĸ�����������������ֵ�Ӧ������Լ���׳ɣ�û��Լ���Ķ����е�����Ҳû�����ǡ� ����ƴ���������ڶ���ŵ㣬��ƴ�κ���Ҳͬ�����Լ����ŵ㡣������������������ģ���������Ϣ����������ʹ�õĴ����Ȼ�ܹ�������������ȴ�����������塣ƴ�����������ǰ����������ר�ҾͶ����������������й��ˣ�һ��ǧ��ǰ��ʫ�ģ��硰��ǰ���¹⣬���ǵ���˪������С���Ӷ������⡣��Ȼ������Ҳ���ع��ֿ���ֵ��ŵ㡣���ֵĶ���ԡ�������ȷʵʹ���ֵ���ϢӦ�ó�Ϊ���⡣��ƴ������һ������ȱ�㣬�������������������ܹ�ʹ���ִ���һ��ֱ�ӡ�����ķ���ϵͳ����������˵�ǰ��ϢӦ�õ�Ҫ��Ҳ�������ʷ��������ֱ���������⣻������˼����һ�ٶ��������й������������ʶ���ٶȵ����룬���Դ˵õ�ʵ�֣�ͬʱ���ڻ���������ͳһ��д�淶����������֡������֣����Ժܷ�����ڼ������ʹ�á�����ƴ�����������˲�δ������ƴ�������ڼ������ʹ�÷��㲢����Ϊ����ƴ���ģ���������ԭ����һ�����������ǡ�ƴ�������ģ��������������ģ����������ġ��������ǰ��������еġ���ˣ�����ֻҪ�����ԣ����������У��ܡ�ƴ����Ҳ���ܷܺ�����ڼ������ʹ�á� �������Ӧ�ã�ʹ��Ϣ�������ٶȵõ���������������ߡ��л�����������һ��ȫ�µ���Ϣ��ʱ�����������������ʱ��ʹ���ִ�����Ϣ���������ģ�����ʵ��һ���������Ƶ����Ҹ����ѳ�Ϊ��ʷ�ı�Ȼ�� �������Ҹ������������Ƶ�Ŀ����ӵ��һ��ֱ�ӵġ�����ķ���ϵͳ��ʹ����ʵ��ֱ��������������뷽����Ƶķ�չ��ʹ���ǿ����˽������������⣺�Ѻ��ֲ��Ϊ�������Ѳ�����Ϊ��ʮ�����ÿһ��������һ������ļ��̷�����Ϊ���롣�����еIJ�������Ȼû����ƴ��������������ĸ���������Ե����ԣ������ֵ���д�ʻ�Ҳ������Ϊ�����������Եġ����ò����ʻ����ֵ��Ⱥ�Ϳ���ʹ�����ų�������ʽ���������������α������ƶ����ֵ��¸������Ҫʹ�������ͱ���������������̽�����о��� 1983�꣬�������������ˡ����ֲ��������ķ��������ۡ������ܽ��˼�ʮ�ֱ��뷽�������ɳ������������������������鲢������ʹ�ò������������뷽���ȶ��ֲ�ͬ�����������ķ�����˵�����뷽���IJ�ͳһ�������ڲ������������ǵĽ�������Ҫ��ͳһ���룬��Ӧ�ü�ϣ���ڡ�ѡ�롱����ϣ���ڡ��淶����ʵ��֤����û���Կ�ѧΪ�����ġ�ѡ�롱�͡��淶���������������õ�Ч��������Ӧ�÷����뿪չ���ֱ���������۵��о����������Լ����ķ������Ͳ�����ϵͳ�о��� �°����������䡶���ֱ����������ʵ����һ����һ���Ѫ��ָ���������ֱ������������������ڲ����Ĵ���������һ�������������ԣ�����Ƴ��ı����룬����ͻ�����α�����ϰ���ʹ���������졣���ֱ�����һ�Ÿ��γɲ����ϳ������ƿ�ѧ����Ϊ������ƿ�ѧ�Ļ���������Ψһ�Ļ������ϡ������ֲ������ں��������ӣ����ڱ�����ʶ�����ʲ������������뷽���Ľṹ������������¶������Ӧ�ù��ɡ�ʵ��������ֻ���ڶԲ��������γɹ�ʶ�Ļ����ϣ�����ʹ����ѧ�������������ɻ� �� �������������� �� �°��ġ�������������˱����룬�ó���һ���°汾��������͵��Բ����������ѱ���Ļ�����Ԫ�ij��ָ�����˵��Ϊ���ʺ��г�Ҫ���Dz����г�Ҫ�����ָ�������Ը�������������Ҳ���г�Ҫ����һ����ѧ�DZ��뼰�����뷽��������������Ϊ���ָ��������������������������ʱ�;�Ӫ�ֶ�ȡ���г����������ԡ��ָ���������ȡ���г��ġ� ���ֲ���������ʼ�����α��롣��������ר��̽�ֹ������˳Ʋ���Ϊ�ָ����ַ������ȣ��������˾��óơ��������ȽϺ��ʣ�����û��ͳһ����Ϊ�ò�����˵���������ɡ� ������ȷ�����Ǻ���Ҫ�ġ����ֺ��Ρ�������Ϊһ�塣�������Էֽ�ΪԪ�ء���ƴ����ĸ�������ܹ�ƴ�����к��ֵĶ���������ƴ�����룬�����Ѿ����˺ö�ķ�������ƴ�����벻��ƴ�����ֵ����Σ�������ͬ���ֺ�ͬ�����Լ��������������ʹ�ã�Ӱ�����������ռ��Ĺ�Ⱥ���ȡ����ż��������Ӧ�õ����̿���һ��ȫ��ᡢȫ��Χͳһʹ�ú��ֱ����ǰ���Ѿ����ʡ����α����ʵ����֤�������Ŀ����ԡ����α�����Ҫ��ֺ��֣���Ҫ�õ����뷽���Ļ������ϡ�����������ϣ������бȽ�ȷ������������������˳�����ǣ�����������һ�¸�����������Ӧ�˶����� ������Ϊ�����������������֮����ȷ�У�����Ϊ�� ��һ�� ��ָ�����м��Σ� ������ ��ָ���ǿɲ�ж�ģ� ������ ����������Զ����ģ� ���ģ� ��ʾ��𡪡�ƴӦ���ǿ���ģ� ���壩 �����������塢���������Եĸ��š� ���������ԣ���������������α�������Ҫ�ġ����������������Ժ��ֲ�����Ӧ��е������Ϣ����Ҫ����Ȥ��������ȴ�ӻ�еѧ�аѡ����������������ֲ������ʹ������Ӧ�˻�е������Ϣ����Ӧ��Ҫ�� �� ���������������� �� �������뷽���ĸ����Dz����Ķ��塣���������¶��壬���ֵIJ�־ͻ��Ϊ���⡣���������Ϊ�κ��˲���Ҳ��Ȩ�����ֺ��֣���Ӧ������ͳһ�����Ķ��塣 ������������ȷ��ָ���������ֲ����IJ�--ƴ���̣����Ƿֽ�--�ϳɵĹ��̣����ֲ����IJ��ַ����Ǻ������ַ�����˳�����������ں��ָ���β����ƴ���´�������˵�������ֲ����Ķ���涨���Ǻ�����ʲô�ط����ܲ�ʵ���ϣ���������ͺ��ֲ�ֹ�����ͬһ������������档������ʲô�ط����𣬾͵��ڶ�����ʲô�ط�Ҫ�𡣡�����Щ���Ĺ�ͬ�����ǣ����ֲ�ֵ�ǰ���Dz����Ķ��塣 �������α��뷽���������һ���³��ֵ���ƿ�ѧ�������Ļ������ۣ�ѧ����δ���������Ȩ����̽�֡��е�ר����Ϊÿ�����뷽��������ˣ������Լ��IJ������塣����Ϊ��Ҷ������Լ���˼��������¶��壬������Ϊ���ڸ������¶����Ƕ���֮�١�����˼�룬ʵ���Ƿ��ϲ����Ŀ��ԣ������²����������ԡ����˶��족�����˼�룩���е�ר����Ϊ�����ʻ������㲿�������»��ֵ�������ʻ���ᡢ����Ʋ���ۡ��㣬�����㲿�ף��ں��ּ��У������ʻ���һ����Ҳ���������֡����ԣ���Ϊ�����ʻ������������������Ϻ��ֽṹ��ʵ�ʡ���Ȼ�����������ϱʻ����ɵIJ���ռ���������ľ��֣�������Ҳ��Ӧ����һ���ʻ����ɵ���С���֡��е�ר����Ϊƴ������IJ����㲿����ƴ��������ࣿû�б����������Է�Ϊ����������  �� �� ����ƴ�����ܵͣ�ʹ��Ƶ�Ⱥܸߣ��㲻�㲿�������ݡ����Ұ벿�� ����ƴ�����ܵͣ�ʹ��Ƶ�Ⱥܸߣ��㲻�㲿�������ݡ����Ұ벿�� ������һ�������Ը÷�������IJ��֣�����Ƶ�ȡ�ʹ��Ƶ�ȶ��ܵͣ��㲻�㲿����������㣬��ô�죿�������Ǻ��ֵ�һ���֡������в���ĸ������֣������Գ�Ϊ������һ�����ּ��еĺ��֣�Ҫ���һ�Ų����嵥�������嵥�е����в���������ƴ��������ּ������к��֡� ������һ�������Ը÷�������IJ��֣�����Ƶ�ȡ�ʹ��Ƶ�ȶ��ܵͣ��㲻�㲿����������㣬��ô�죿�������Ǻ��ֵ�һ���֡������в���ĸ������֣������Գ�Ϊ������һ�����ּ��еĺ��֣�Ҫ���һ�Ų����嵥�������嵥�е����в���������ƴ��������ּ������к��֡� ������������뷽���Ļ������ϣ�������ܶ��Զ�������ƾ��ݿ����������Ķ��壬���Ƕ��ԣ������嵥�����Ƕ�����������������������ѧ����Ʊ��뷽���ĵ�һ���� �ṩһ�������ַ����ĺ��ֲ����嵥����ס�����嵥�еļ��ٸ�������ÿ��������Ĵ��룬���Ǿͻ�֪���κ�һ�����ֵĴ��룬�Ϳ��Ա���������ʱ�Ķ����ԣ����������IJ��㡣������Ϊ��ס���ٸ��������ף�����������ѡһЩʹ��Ƶ�ȸߵģ���Ϊ��Ʊ��뷽���Ļ�����Ԫ���Խ���ʶ�Dz��ϵ�������������Ϊ������������������Ŀ�ѧ�������������⣬��Ӧ�ôӿ�ѧ�ķ�����չ��˼·�����ٸ����������������䣬��Ȼ�����ѡ������ܽ����ǹ���Ϊ��������ķ���ϵͳ������ϵͳ���䣬�������룬һ�����һ�࣬һ������һ�����������ͻ������½��� ������ÿ������������߶�������������¶���ģ���ֺ��֡������������������࣬����Լ��������IJ�������ˣ�������壬��������ѧ�ģ����Ǻ������α������ѧ�ġ����ʾ��ͼ���ң� 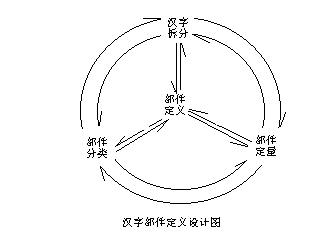
��ͼ���������������Ҫ��Ҫ��������ֵ�ԭ��λ�����������ݣ��Ľ��ͷ���ķ����������߱�����Լ����������ƶ�����ͼ����������֡����������࣬���߹�����һ���Բ�־����������Զ������Ʒ��࣬�Է�����Լ��ֵ�ϵͳ�ṹ�� ˵����һ�㣺û�в�֣��ж��ٲ����Ͳ���ȷ��������������û�ж������Ͳ��ܽ��з��ࣻû�з��࣬�Ͳ�����Լ��֡�����һ������������Լ��ѭ��ͼ����֡����������࣬���������ڶ��壬����Լ����IJ����� ͨ��������ͼ�����ǾͿ��ԡ���ͼ��������������ͼ�������¶��塣 �� �ġ��������� �� 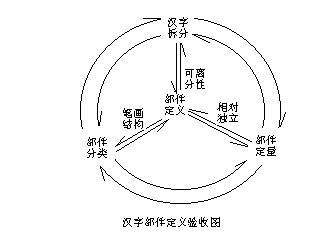
�����Ͻڷ��������ǰѲ�������Ϊ��ƴ�����ֵĻ�����Ԫ�������С���Զ����ġ��ɷ���ıʻ��ṹ�������ʻ���Ϊ��������������ɼ������ı��������ж���һ����Զ����ԣ����ǿɷ����ԡ���Զ������������ڱʻ��ṹ�����ڣ����Ǹ������Ҫ���ն���������ա�ͼʾ���ң� ��ͼ˵�������������������IJ�֡�����������Ѿ����������γ���һ�����Լ��ϵͳ���ö����Ѿ�ʵ�����Ҫ�� ��һ���ɷ����ԡ��ɷ������Dz����Ķ�̬���ԣ������벿��֮����ƴ�Ϻ��ֶ�������϶�����ּ�϶���Dz�ֵ����ݡ� ��϶���Է�Ϊ���Լ�϶�����Լ�϶�� ���Լ�϶��ָ�������벿��֮�䣬�����ԵĿ���һĿ��Ȼ�ؿ������ļ���� ���Լ�϶��ָ������ ��1��������ͬ�ij��ֲ���֮�䣬�硰�š��ġ�ʮ���ڡ�֮�䣻 ��2�������ʻ�����ͬ�ıʻ��ṹ��֮�䣬�硰ʾ���ġ�����С��֮�䣻 ��3��������ͬ�ıʻ��ṹ��֮�䣬�硰�硱�ġ�Ի����Χ����ʮ�����棩��֮�䣻 ��4��һ�����ֲ�������һ���ʻ��ṹ��֮�䣬�硰ռ���ġ� ���ڡ�֮�䣻 ���ڡ�֮�䣻 ��5��һ��Ʋ����һ���ʻ��ṹ��֮�䣬�硰�ԡ�ǧ���ġ�د����Ʋ�ʣ��롰Ŀ��ʮ��֮�䣻 ��6���롰�ꡱ����ĺ����ӻ��ཻ���硰ꫡ��ҡ���������ʵ�Ƿֿ������������������ǵıʻ����ƺ�λ����ͬһ�����ϣ�Ϊ����д������֣����㣬����һ���ˣ�����������Ҫ������ǣ�����ָ�����ԭ������ò�� ������ֲ�����ָ��������IJ������硰��ľ���ڡ��ա��ȡ��ʻ�������ָ�ʻ���д�ķ������������¡��������ҡ� ��������Զ����ԡ���Զ������Dz����ľ�̬���ԣ�����ά���˻����ʻ��ṹ�鲻�ٱ��������Ϊ�����ʻ����ֱ�֤�˷��������ĵ����ʻ���Ϊ�����ġ��Ϸ���λ���� �ʻ��ṹ����ָ�ʻ�֮�乹��������Ľṹ��ϵ�������Է�Ϊ���ֻ������ͺ������������ͣ� ��1�� �ʻ���ʻ����룬�������ͣ� ��2�� �ʻ���ʻ��ཻ�����ཻ�ͣ� ��3�� �ʻ���ʻ���ӣ�������ͣ� ��4�� �ʻ���ʻ���Ӻ��γɰ�Χ���ư�Χ�ͣ� ��5�� ���ֻ����ʻ��ṹ��Ϲ��ɵģ���ij�ֻ�������Ϊ���ӵĽṹ��ϵ�����ּ��͡� �ּܵ�������ÿһ��С���һ����ͬ������Ϊ���ӣ�Ȼ�����ӱʻ���ı���Σ��γɵ���� ���顱��ָ���������������ϱʻ�Ϊ�����ṹ���ɵIJ������ں����У����ǿɷ���ģ��Ժ����е�����������˵��������Զ����ġ� �ʻ���ʻ����첿�������ļ����Ϊ�ṹ��ϵ���ṹ��ϵ�����ھ��ԣ�����Լ��ֵ����ݡ�Ϊ�˷�ֹ�������������ʻ��ṹ�飩�ʻ�һ��������ȷ�ϣ������ʻ��ṹ���ܲ�ֵ�ԭ����Ϊ����������Զ����ġ� �� �塢��������IJ������ �������ֻ�пɷ����ԣ���ֱض�Ҫ�ʻ�������Ϊ��ˣ��е��˲Ż���Ϊ���ֵĻ�����Ԫ�DZʻ���ֻ�бʻ����Ų����ٲ���ȥ�ˡ��������Ķ�̬�����������ġ����ǣ����ּ����ͼ������Ӧ�õ�ʵ���������ǣ��ں�����ʻ�֮�䣬��Ӧ����һ���м��Ρ���������ȱ�������Σ�����Ӧ�á�����м��Σ���������Զ����ġ�ֻ����Զ�����������Լ���Ŀɷ����ԡ���ˣ���Զ��������ľ�̬���ԡ� Ȼ������Զ����ĸ������ģ���ġ�����ָ���ıʻ��ṹ��ͻ����ʻ����°�������˵����������һ�����ʻ��ṹ�顯��ô��Ӧ�����������ϱʻ�������Ӧ���γɿ�״������һ���ཻ��ıʻ���һ���ṹ�顣������ճ���ıʻ���һ������һ���ṹ�顣���������ȳƵ������ıʻ���һ���ṹ�顣�ġ���տ��ڲ��ıʻ�����������ճ���ģ����������һ���ṹ�顣���ڵĵ��һ�㸽��������塢�����ĵ��һ�㸽�����������Ľṹ�顣��������Ľ����ѻ�������� ���硰���������������ཻ��ıʻ��ṹ�飻���ӡ�������������ճ���ıʻ��ṹ�飻���������������������ıʻ��ṹ�飻������������������Χ״�ıʻ��ṹ�顣������ȿɺܷ���ط��뿪����������Զ����ġ���ν��Զ�������һ����˼�����������Լ���������������һ�ۿ����������硰����������ǡ��ߡ����ұ��ǡ����������߶����Զ������֡����硰��������Ի����һ����ʡ���Ի���Ƕ����ġ��顱����һ����������ô�죿����һ�ۿ�������Զ����ģ�������Ϊ��������������� �����Լ�϶�IJ���������һĿ��Ȼ�ؿ�����������Щû�����Լ�϶�ġ�����һ���ֵIJ���������������Լ�϶�ĸ�����Լ�϶Ҳ������֪���������������ֵĹ����У��ȶ��ǽӴ�һЩ�ʻ��ṹ���֡���Щ�֣��е��Լ�����һ�����ṹ�顱�����硰ʮ��������ṹ�������ڡ�����Χ�ṹ��������ƴ�����Ǹ����š��֣���Ȼճ��һ�𣬵�����������������ܹ����ܵģ����硰�����롰С����ƴ�ɡ�ʾ�����������ֲ�ͬ�ıʻ����ƣ���ֿ�����Ҳ���Խ��ܡ������Ϊ��һ������ ���������Ϸ����Dz������ܵġ�����Ϊ������������������Ϊ������Ӧ��������ӡ��� ���������Ϸ����Dz������ܵġ�����Ϊ������������������Ϊ������Ӧ��������ӡ��� ������������ӡ��IJ��ԭ�����ڡ��������������ܣ������ڡ�ء������������ȴ�����ѣ�Ӱ��ֱ��ԭ�����������ϰ�������ʲô���������������ѧԺ����������������һ���ܺõ��������㷽�������ֲ���=3���ʿ鲿��=2�����ʲ���=1������������Ϊ������ʮ�����������dz��ֲ���������������Ϊ6����Ϊ���ۡ��ɡ���ֻ����5����ء���������������Ϊ��һ����������һ�� ������ ������ ���������Ȳ�Ϊ�������|���������� ���������Ȳ�Ϊ�������|���������� ����������د���������������������ܡ���Ϊ�������ǵ���֪�����У��Ժ��ֲ��Ϊ�����Ľ��ܣ����ֲ���>��ʲ���>���ʲ������ں����У���һ��������ġ������桰��ְ�������Ǻ��֣����Dz��������DZʻ����������ϼ���������ʱ��һ�������ڵ������ڷ���״̬��ʱ�������Ϊ���ֲ����� ����������د���������������������ܡ���Ϊ�������ǵ���֪�����У��Ժ��ֲ��Ϊ�����Ľ��ܣ����ֲ���>��ʲ���>���ʲ������ں����У���һ��������ġ������桰��ְ�������Ǻ��֣����Dz��������DZʻ����������ϼ���������ʱ��һ�������ڵ������ڷ���״̬��ʱ�������Ϊ���ֲ����� ���ö����ֺ��֣���Ҫ�ܶ���������������е�����Ϊ�� ��Ӧ����һ�����顱����Ϊ�����Ǵӡ�ֹ���ݱ�����ģ��������˵Ľš������ô��������������ˡ� ��Ӧ����һ�����顱����Ϊ�����Ǵӡ�ֹ���ݱ�����ģ��������˵Ľš������ô��������������ˡ� ���ߡ�����Ҳ���ܲ��Ϊ�������顱�ˣ����ء�ֻ����Ϊ���⡱��Ҳ���ܲ��ˡ������뿪����Բ�ֵĸ��ţ���������ǿ���Ϊ�����ڵ�����£�����һЩ�ʻ��ṹ���š��Ѻ��ֲ��Ϊ������Ҫ���ϵ�ǰ����֪��������������Ҫ�ġ�ΪʲôҪ˵����ǰ�ġ������硰�㡱������ġ��ڡ�������ġ� ���ߡ�����Ҳ���ܲ��Ϊ�������顱�ˣ����ء�ֻ����Ϊ���⡱��Ҳ���ܲ��ˡ������뿪����Բ�ֵĸ��ţ���������ǿ���Ϊ�����ڵ�����£�����һЩ�ʻ��ṹ���š��Ѻ��ֲ��Ϊ������Ҫ���ϵ�ǰ����֪��������������Ҫ�ġ�ΪʲôҪ˵����ǰ�ġ������硰�㡱������ġ��ڡ�������ġ� ���˵ı��壩����Ӧ����ֲ�������ô���ѵ��еġ����������Ҳ�������ܡ� ���˵ı��壩����Ӧ����ֲ�������ô���ѵ��еġ����������Ҳ�������ܡ� ���ö���ֽ⺺�֣�����ط�����һЩ���ѣ����硰ϰ���������ٲ�Ϊ���S���������� �������Բ�Ϊ�� �������Բ�Ϊ�� �� �� ������Щ�������𣬻��Dz����е��˽��ǿ�����ֵIJ��û�й��ɣ��Ϳ������⣬�ⲻ�ǵ�������Ϊ����Щ�Ǻ����м�����ģ����ң����Ը�������ϵ������������ȷ�����Dz��� ������Щ�������𣬻��Dz����е��˽��ǿ�����ֵIJ��û�й��ɣ��Ϳ������⣬�ⲻ�ǵ�������Ϊ����Щ�Ǻ����м�����ģ����ң����Ը�������ϵ������������ȷ�����Dz��� �� ���������嵥 �������ѧ����������˵������֮��ʶ��Ҳ�����ڲ��ɷ֡����ܷ�һ��Ϊ���֣���㻭�ز���ȱ����ѧ�������ӣ�������һ������ѧ�����ֹ淶����ѧ�����롣�����������Ӧ�õĿ�Ҫ���ֱ�����Ƶķ�չ���������ר�ҵ���ҹŬ�����Ѿ�����ʹ�����������ʵ�� ���������ǻ������ٴ�ǿ�������������Ҫ�Ժͱ�Ҫ�ԣ�û��������û�в�ֵĽ��ͷ����������ϵ��������֮�����ܹ��õ�ͻ�ƣ���������һ����ѧ�IJ������壬���Դ�Ϊ��������һ�Ų����嵥���Աʻ��ṹΪ�������������ϵͳ���´�������˵���������˶�����û���ʹ��δ�����������嵥��Ҳ�ܼ������еĴ���������������˶Բ���������Ӳ���������ص�����������Ŀ�Ԥ֪�ԡ����������ߺͽ����ո����ڶԱ������386�������嵥������һ���������Ѳ�������ѹ��Ϊ368�������ٺϲ�Ϊ352��������Ϊ��ѧ���㣬������ʻ��ṹ�����Է�Ϊ�߸����¸����ֲ����嵥�� 

�������嵥�У����м���������IJ������硰�����Ҫ��Ҫ��Ϊ���R���V������������Ҫ��Ҫ��Ϊ����һ�������֮��ĺô��Dz������������ˣ������ǡ���С���ʧ�ˡ�����������Ƶ�ȡ�ʹ��Ƶ��Ҳ������һЩ���á����硰���������������������һ���������ʣ��𣬻��Dz��𣿱�����Ϊ������嵥ֻ�ṩһ�������������Ĵ���������ȫ��ר�ҹ������ۡ����ᡣ ���Ų����嵥��ֻ��352�����ȡ��ĸĻᡱ���ƶ���648��������ѹ����ʮ��֮��ǿ�����ṩ��һ������ķ���ϵͳ��ʹ�����ࡢ�����벿�������ܹ������е���ϵ�����嵥�еIJ�������������Ҫ�����⣬����������������Խ���֤����˵�����������嵥�еĺϸ��ԣ�����˵���ڵ�ʮһ�ڣ����嵥��Ϊ�߸��ͣ�ÿ������6��8���࣬������һ������������ÿ�����еIJ�����Ҳ�����α仯����������˵���ڵ�ʮ�Ľڣ���ÿ�����еĴ��룬��������������������������Ϊ��������Ϊ����ӳ�䣨��Ӧ�������� ͨ�������嵥�������ܸ������⣺���ֱ���������Ǽ��������ǹ���ͷ������嵥�еIJ���������ϵͳ�����뷽���;�����룬���п����۵ĵط�����ͬ�ķ���ʹ��룬�ֻ������µı��뷽����������ί�ͽ�ίҪ��ͳһ���ֱ��룬����Ӹ������𣬼�����ͳһ�����Ķ��壬Ȼ��ͳһ�����嵥������������ϾͿ��Ծ������۷���ʹ��롣�������뷨��������������һ�����������ø������ƺ���ϵͳ�Ĺ�˾�Լ�װ�Ͼ��ǡ���Ϊ��ÿ�����ֹ���ϵͳ����������һ���Ŀռ䣬���뷨�ij�����ƣ������Ǻ����ѵ��¡� �� �ߡ������ķ��� ��������˼��һ�±��뷽������ƣ��Ϳ��Է����������뷽���IJ�������ͱ��뷽��������һ�������塣������֣���������ñʻ������������ͬʱ���Ѿ��ڸ��������ָ���������ˣ����е������������������������ס������֣������ʱ��Ҳ���ڸ����������ˡ�ֻ��Ǯΰ���������������ǶԺ��ֵ�������֪�����������Ƴ����ĺ��������ǾͿɷ��ֲ����ķ���ͱ���루��ӳ�䣩�ܹ���Ϊ������Զ����IJ��֡����Ǻ������α����һ�ιؼ��Ե�ת�ۡ������������������������߿��ԱȽ����ɵ�ѡ���ʵ��Ĵ��롣��ˣ��������Ҳ�Ϳ������ɵ�����ѡ����һ��ӳ�䷽�����ѧ�� ������ô��Ϊ���ڷ�����ϣ��°������������˲�������ĵڶ�����̱���������ط������ʻ��ṹ�顱���������������ʻ��ṹ�ͺ�һ����Ȼ�����嵥���ʻ��ṹ��=�����������ʽ��ȡ��������ѡ����������648������һ���ӽ���380�����������һ�η�Ծ�� ����ͼ�����һ��������������档�Բ����嵥��˵�����ٸ���������ʲô������Ϊ��ʮ���������𣻼�������ʲô����ʹһ�������ۼ�һ�������IJ����� ���ٸ�������������ֱ�ӷ��䵽������ȥ��ֻ�ܷ�Ϊ������Ρ���������ȷ���������һ��Σ������λ�����ڶ���Σ���֣�루֣������á������������á�λ����������Ϊ����ɢ������Ҳ����˵��ʹ��������һ���Ŀ۹��ϡ���ʼ�ʱ�����ɢ�����ϣ�������������Ը������Ϊ�����ֵ���д���Ǵ������ҡ��������µġ�������ʼ���Ժ�Ӷ࣬����Ϊ�Σ��۱����١�������ȣ������ٷ���ȥ������������ͣ�ͷ����Ϊ���ᡢ�������������ۡ�����Ʋ���ۡ����ر�ࡣͷ����Ϊ���ᡢ�ࡱ�����ࡢ���������ࡢƲ����û�С���Щ��λ�����ͳ��˿�λ��֣��֪�������λ�������������ã���ֻ��ʼ�ʡ��ñ��ν��ָ�������������Ϊ���࣬�ֱϺ��ٷ�ΪС�ࡣ֣��ģ��������У�ʼ������ռ�˸���Ԫ�����õڶ����ʻ���λ��ʵ�ʾͳ����������š�Ҳ����˵��������������Ҫ���á� ��������������Ϊ�����ࡢ�ʻ��ࡢ�����ࡢ�����࣬Ҳ���Լ������趨��û���κ����ݡ���ˣ���Щ���������ʹ���ֲ����γ�һ������ġ����������ϵ�������ַ���������ϵͳ�����ֵIJ���ϵͳ��ҲӦ��������ϵͳ������������ϵ�������ԣ�Ҳ��Ȼ�ǿ۴��ڵģ��������ڲ����Ķ���֮�С� ��֮�������������������������ǡ����ڡ����������������Ƕ����������档����֡�֮�������ڡ����ࡱ������֡�֮�ƣ����ڡ����ࡱ����������Ķ��壬ֻ�в�ֽ��ޣ�û�з���ķ������������Ͳ��ܴ��ڡ� ���ñʻ��ṹ�Բ������з��͡����࣬����ʹ�����ܹ���һ��������ϵ����������������δ���ռ������ĺ��ֲ����������������ֻ��6763������������ֿ����ʮ���ڴ˵���û���ռ�������������һ���۵ġ�����ķ�����ϵ�����Ǿ�û�а취ʵ��ȫ��������Ϣ���������ϵIJ����嵥�У����ǿ����˽��������ϵͳ����Ȼ��δ����ĺ��ֲ�����������������ʲô���ӵģ�ֻҪ�ǴӺ����в�ֳ����ģ����Ƕ��Ӳ������߸��ʻ��ṹ���ɵ����ͣ�����������ɲ��˵������࣬���ֻҪ�Ժ������Ϳ����ˡ� �� �ˡ����ֲ�ֹ��� ���ݲ������壬�����г������嵥�����Բ�������ϵͳ���ࣻ���������嵥���ɳ����ֲ�ֵ�����ԭ�� ��һ����϶��֣������еIJ����벿���������Զ��������ԣ��������ڼ�϶����������Щ��϶�������ֲ��Ϊ������ �����������ʻ��ṹ���𣺻����ʻ��ṹָ���������ϱʻ����������ʻ��ṹ���ɵIJ������ܲ�֡����������͡��ཻ�͡���Χ�͡��ּ��͵���Щ�������ܲ�֡� ��������������ָ�Ѿ����벿���嵥�еIJ������ܲ�֡� �������� ��һ�����벻�𣬳������ȣ�������ȣ� �������ཻ���𣬡��ڡ����������ס����⣬�����ཻ���⣨�ġ��⣩�� ���������ڲ����ϵ�Ʋ��һ�ɲ����������ء��ߡ�����������Ʋ����ɵIJ������� ���ģ����ꡱ���ಿ�������������쳤�������������ʻ���ӻ��ཻ�ߣ��ú��һ���������ã� ���壩�γɰ�Χ���𡣰�Χ���ڵ�ճ���ʻ�����ճ���ڰ�Χ����ıʻ��ṹ�������ʻ�Ҫ�������Χ���ڵĵ�����ʲ��𣬡��桱�����⣻ �������γ��ּܲ����м�һ�ᣬ��ͷ�е�����ʵ�ס��һ�ɲ��𣬡�ا�����⡣ ����������ֹ���ֻ�е�ʣ��Դ�Ƿȱ���������ֺ�Ʋ��һ�����������ʻ���Ծ�������������У���ʿ��Ե�����ɲ�������岡��͡�ڢ�������Ʊ��ǣ�����ʬ����������Ȯ��̫������־ͻ������鷳�����������Ƿȱ�Ժ��ֵIJ����˵�����ް�����ˡ� �� �š����ֲ�ַ��� ���ֵIJ��ǣ�浽���ֵĽṹ��ϵ�������Ǻ��Ͻ��Ĺ��������ǣ��б�������߾�Ȼ��Ϊ��Ϊ��ʹ���̴�����֣����Բ��˺��ֵĹ淶��ֻҪ������Ҫ���Ϳɡ��������ġ������ǰѡ�������Ϊ��һ��С������������Ϊ���ߡ�С��������Ϊ���ȡ��ߡ����������������������������ֽ��������ߵIJ������Ӷ�ʹ����⡰���ֱ��롱����ΪֻҪ���֣��ͻ����ֹ淶����˷���һ�С����ֱ��롱��������Ϊ��������Ϊ�˵õ���������ô������ʲô���ж����ʲô�ã��ں�������λ��֣����������и�����������˭Ҳ��ʵ����ȷ�IJ�֡����Ҫ�������ж��壬����߱�����ݲ����Ķ���ȷ�����ֵIJ�֣��õ������嵥�����ĵ��Ľ��Ѿ������˲����Ķ��壬���ڵ����ڽ����˲����嵥�������嵥���ɳ���ֹ����Ա�Բ�ֻ����һ��ȫ��ķ��������ַ�������ʹ������ʶ�����Ķ��塢�嵥������ȹ�������ȷ��� ��һ���Ƕ�ÿ�����ֵIJ�������ͳ�ơ�����������嵥������һ���ֿ�3755�����֣��У� ��������111�� ռ 2��956% ��������629�� ռ16��751% ��������1249�� ռ33��262% �IJ�����1068�� ռ28��442% �岿����489�� ռ13��023% ��������160�� ռ4��261% �߲�����49�� ռ1��039% �˲�����8�� ռ0��213% �Ų�����2�� ռ0��053% һ���ֿ�3755���֣�����111���������֣���3644���ಿ���֡������������ġ��岿���֣�����3435���֣�ռ91��48%������˵��ƴ����ĸϵͳ���ļ����֣��������Է�ӳ��ȫ��������Ϣ�������ߡ��ˡ��Ų��������ļ�ȡ�룬Ҫ�Ե�һ�����ֲ���������ռ�����Ѻ������ˡ� ���ͳ��˵������Զ����ıʻ��ṹ����Ϊ���ֵĻ�����Ԫ��������������ʵġ���Ϊ�����ݸ����������ּ�����ͳ�ƣ������������ѡ���ļ����֡����ӵ籨�뿪ʼ�����Ǿ�ȷ���ļ����֡���Ϊ�����ܺ����������������������ͨʹ������ֻ������ǧ�������ᳬ����λ��������˵���ļ������Ǻ���������ѵ�ѡ�����Ĵ�С��Ҳ��Ȼ�и�����ʵ�ѡ������ѡ������ܷ���ȷ�ط�ӳ����������Ϣ����Ϊ�������������η�ӳ��Ϣ���ڲ�������֮ǰ��������α����Ѿ������ˡ����α��밴��˳�ֽ⺺�֣���ʹ���ִ���ܷ���ع����������С����ǣ����α���ȴ����ӳ���εĽṹ��Ϣ����ʹ������Ϣ��Ĺ��࣬�����˲�����������ơ� �е���Ҳ����Ϊ���ּ������ˣ�Ϊ�˱������룬������Ϣ��ģ�Ҫ������ֲŶԡ���ʵ��Ȼ����Ϊ�����ּ�������������֣����Լ������룬��������߹���Ч�ʡ������ֻ����Ǹ�ʹ��Ƶ�ȣ��������ּ�����������͡����ּ������������ӣ�ֻ�����������ʣ��������ٶ��ء�������˵���뿴����ʮ������������� ���������գ��Բ�ַ�����Ϊ��֤���ܹ�ʹ���Ǹ������⺺���ǡ�ƴ�����֡�����¸��ͬʱҲ���Լ������ⲿ���Ķ��弰������Ҫ���塣���ֱ����ͳһ�������ڲ��������ͳһ�� �ò����嵥����ÿ���֣��Ϳ�֪��������β�֡����硰�硢�ˡ���ƴ�����ǡ�������������ҳ������Ȼ���C���͡����������һ������Ҳ֪�����ò�Ϊ���C���硢�ˡ��� һ���ֿ�Ķ���������629�������������ϵ��֣�������Щ�ֵĵ��ӣ���ˣ������������֣��������ȸ������һ�ߡ� �ڶ�������ֻ���������������֣����������֣���������Ķ������֣���������֮�䣬�����Եķָ����������Dz����Ķ����У�������ָ�����Ϊ���Լ�϶���Ѽ�ǰ���������Լ�϶��ֺ������������֪������629�����������У������Լ�϶����546����ռ86.8%�����Լ�϶��ռ�ı�����ô�࣬˵����϶��ֵ�ԭ��û�д���˵�������εĽǶ��о����֣������ƴ�κ��֡���һ����ĺ����ԺͿ��ԡ����е��ֲ�����ƴ�εķ���������ģ����硰¹�����Ŵ����� ���������飬��¹���ų�Ϊ����������ӣ������ĸ��顣���ǡ��ѱ䡱�����ѱ䡱�����ִ�����һЩû������IJ�����Ҳ������Ϊ��û����������ֲ��ϡ� �������������������һ��û�����Եļ�϶��������֪������˵�����Բ�֡������Լ�϶�Ķ���������82����ռ13.04%�����У� ���ݡ�����Ʋ��Ҫ����ԭ���༴Ʋ����ʻ��ṹ����Ӵ��������Լ�϶����25����ռ3.97%�� �硢Ѫ���������������ء�ë��ţ����ǧ���ɡ�����ʧ���֡��̡��ס��ҡ��ء������š��ԡ��졢�ۡ�����ʸ �����Ͳ�������ʻ����Ʋ�ͬ�������ʻ���ӵ���19����ռ3.02%�� �����ġ��ࡢ�����С�����ʾ�������ơ������ࡢ�֡��𡢲���ƥ��ҵ���¡��ʡ�Ԫ ��Χ����ıʻ��ṹ��ʻ���ӵ���13����ռ2.07%�� ռ���ء�¬�������䡢�С����桢�ס�Ƥ���á��ߡ�ֱ ������ͬ�ıʻ��ṹ����ӵ���12����ռ1.91%�� �ᡢ�á�˦�����������硢է����ϡ�ȥ���ꡢũ ������ӵ���2����ռ0.32%�� ̫��ר ���ꡱ�ֺ������������1����ռ0.16%�� �� ���ڿ��ƶ��Ե�2����ռ0.32%�� �ѡ��� ���������ʻ��ṹ����ӵ���7����ռ1.11%�� �졢�������ޡ����������� ֻ��һ�����͡�����֡�ռ0.16%�����͡�Ҫ��Ҫ���Ϊ�� ���]������ҿ������ۣ��ڱ�����ͺ���ƴ����ĸ�IJ������У��Ѿ����ɡ��͡���ɵ��֣��У��ѡ�ɫ���ʡ��ҡ��ˡ��֡��ޡ��Ρ��̡������С���Ϊ����Ϊ�ѵ������ǣ�����һ����Χ�ṹ�����ݡ��γɰ�Χ���𡱵Ĺ涨���Ͳ�Ӧ�����ں�����һֱ����Զ����ģ�û�а취�ӱ�ĺ�����֤�������롰�]�������ֿ�������Ϊ��Ϊ�ѵ������ǣ���һ���ѡ��͡���Ϊ�����]��������Ӣ����ĸ���ƣ�����������룻������������ֶ�������5����������ֿ�������������Ԫ���������룻���������롰�����ȡ��ѡ����ƣ������ֿɲ𣬡��͡���������˴����� ���]������ҿ������ۣ��ڱ�����ͺ���ƴ����ĸ�IJ������У��Ѿ����ɡ��͡���ɵ��֣��У��ѡ�ɫ���ʡ��ҡ��ˡ��֡��ޡ��Ρ��̡������С���Ϊ����Ϊ�ѵ������ǣ�����һ����Χ�ṹ�����ݡ��γɰ�Χ���𡱵Ĺ涨���Ͳ�Ӧ�����ں�����һֱ����Զ����ģ�û�а취�ӱ�ĺ�����֤�������롰�]�������ֿ�������Ϊ��Ϊ�ѵ������ǣ���һ���ѡ��͡���Ϊ�����]��������Ӣ����ĸ���ƣ�����������룻������������ֶ�������5����������ֿ�������������Ԫ���������룻���������롰�����ȡ��ѡ����ƣ������ֿɲ𣬡��͡���������˴����� ͨ�����Ϸ��������ǾͿ���֪��87%���ֿ���һĿ��Ȼ�زģ����������Ҫͨ�������Ĺ�����в�֣�ֻ�и����������Ҫ���۵ġ����硰ؤ������Ϊһ�������أ����Dz��Ϊ�� �������������ּ��٣�ֻҪ����ͳһ�涨�����ˡ�����������ֻ�����˺��������֣�ֻҪ��һ���ֽ���ã����������ϵ��֣������������ǵĵ��ӣ���־Ͳ����������ѡ� �������������ּ��٣�ֻҪ����ͳһ�涨�����ˡ�����������ֻ�����˺��������֣�ֻҪ��һ���ֽ���ã����������ϵ��֣������������ǵĵ��ӣ���־Ͳ����������ѡ� �е���˵�����������֣��е���˵�����������֣���������һ��ƴ�����ֵ��¸�����ý��ܲ��ˡ������Ǻ��Ρ�������Ϊһ������֣������������֣����������������������֣��������⣻������ƴ�����֣��������Ρ����Ǵ����ֲ�ͬ�Ƕ������˺��ֵı��ʺ����й��ɣ�������ų⡣��ȥ֮����û��ƴ�����ֵĸ�������ڹ�ȥ����û�����α������Ҫ���������������������Ҫ�������µ��������µĸ��Ȼ˳�����¡� ������ķ����п��Կ����°��������Ժ��ֲ�ֵĹ��ף������������������Ʋ�ʵ�һ�ɲ�����͡��ꡱ�ּܵĴ��������ɽ���˺��ֲ���е��ش����⡣Ʋ���ڹ������Ǻܻ�Ծ�ıʻ�������������ṹ���硰ʮ�� ������ṹ����Ի��Ŀ����Χ�ṹ�����f�����ּܽṹ����������Ʋ�ʣ��ͳ�Ϊ��ǧ��ţ���ס��ԡ�����ʧ���ȣ�Ӱ����࣬���Ʋ�ʣ����ǹ���ͷ����ˡ�һ�������ܼ������ಿ�����Ӷ����ѧϰʱ�ļ�������˵������������ҪѰ�ҵ����ι��ɡ� ������ṹ����Ի��Ŀ����Χ�ṹ�����f�����ּܽṹ����������Ʋ�ʣ��ͳ�Ϊ��ǧ��ţ���ס��ԡ�����ʧ���ȣ�Ӱ����࣬���Ʋ�ʣ����ǹ���ͷ����ˡ�һ�������ܼ������ಿ�����Ӷ����ѧϰʱ�ļ�������˵������������ҪѰ�ҵ����ι��ɡ� ���ꡱ��Ϊ���ԣ�ƴ��ʱ�����Ҳ࣬�����Էָ����ĺ����ֲ��࣬�硰Ϸ��ʽ���䡢߰���ߡ�߯���䡱�����硰�ء��ԡ��ɡ�갡������С������ȣ����ʳ���������һ����ɲ�ֵ����ѡ��°�������������������ꡯ�ּ��࣬���������쳤�������������ʻ���һ�ɴ��жϿ���������涨���䲻ʮ�����ƣ��������Ѿ�Ϊ����Ľ������ͻ�ƿڡ�˵������������Ϊ����һЩ��Ҳ�����쳤���������������ʻ����硰ʽ���䡢߯���ȣ���ֺ��Ҫ��Ե�ʵ�����һ���ʻ�����������������һЩ��Ť����ˣ����߽�����Ϊ�������ꡯ�ּ��࣬���������쳤�������������ʻ���ӻ��ཻ�ģ�һ��һ�����á��������ֱ�ֻ�������������Ͳ��������������ˡ� �������������ij���ṹ�鶥�ϻ���µģ���ʻ����ƹ�ϵ�������������һ��ֻ�ܽ������ʻ����Ʋ� �������α���IJ����嵥��֮�����ܹ��ӡ���ѡ��������������ѳ�����ʵ�ֿ۵IJ�֣���Ҫ��Ǯΰ�����°�����λ�����Ĺ��ס����������ֲ�ֹ��ɷ���������79ҳ�������ײ���֤���� �� ʮ�������ȡ�� ��ֺ�ȡ����������ͬ�ĸ������������������߰����ǻ����ˡ����ǿ��Է���֧���������ļ���ʶ����IJ�ֹ��� ��1.һ�����־������������˽ṹ����ĸ��ַ���ɵ��ַ��������确㰡������ࡢ�硢�����ڡ����ֻ�ܲ�������ַ����������һ����Ϊ���ĸ��ַ������确���������ܡ������硢ؼ�����ֻ�ܲ�������ַ���������һ����Ϊ�����ַ��⣬�ٽ����ֱ�����Ϊ�����ַ��� 2.һ�����ֵ�ijһ�ַ��������ıʻ������ıʲ��ٲ��确����Ϊ�ַ����ܲ�֣�����Ϊ���������֡� 3.ǰһ�ַ����һ�ʻ������������γ���һ�ַ������������ȥ��ֱ���ıʻ���Ȼ�Ͽ�Ϊֹ���确ʾ�������Ϊ��ء���ˡ����ܲ�Ϊ������С���� 4.�����ĸ��ַ����֣��á�ǰ����𡯵ķ�������ȡ�ĸ��ַ������磬������������ء�ء���ˡ����С��ء����������ಢ�ġ����� ��Щ�涨��ʵ����ȡ���������Dz�ֹ��� ���ں��ֵIJ�֣��°��������Ĺ����������ױȵġ�������ģ�����Ʋ�ʲ����ꡱ�ֽṹ�ͶԳƱʿ鲿����Ĵ����ȣ�������˵�Ǿ��������õIJ�ֹ����ǣ�������ġ���Ȼ�������͡��˹�����������������Դ�˵�������ȡ��IJ�ͬ��ȴҲ���ڸ����ϵĻ���������Ȼ������ӳ�������νṹ�Ŀ۹��ɡ��˹���������һ�ֱ�������۰��š���Ȼ�������˹������Ļ����������ڱ������еġ���ϲ����������dz°���������˵���˹�������������Ϊ��������Ӧ���ǿ۴��ڵģ���Ҫ����һ���˹�����������������ǿ�ӽ�ȥ�� �еIJ�������Ȼ���Ǻͱ�IJ���ճ��һ�����硰�����ѡ��ȡ��������Dz���Ϊ�� ���͡��]����Ϊʲô������Ҳ����ܣ���Ϊ�������͡��]��֮�䣬�����ƶ���Ϊ������ͬ���֣���������ƶ��ԡ� ���͡��]����Ϊʲô������Ҳ����ܣ���Ϊ�������͡��]��֮�䣬�����ƶ���Ϊ������ͬ���֣���������ƶ��ԡ� ����������Ϊ���������ֵIJ���������Ҫ�ƶ��ϸ�ĺ����з�ԭ��������˵��ԭ��Ӧ��ʹ�κ��˶��κκ��ֵ��з�����Ψһ�ģ�����ʵ�������������ں�������̫�࣬�ṹ���ӣ���������ȷ���з�ԭ����һЩ�ֻ�������⡣����������û���뵽���ǣ�����û�ж��壬���ԭ��ֻ��һ�����롣���ֵIJ��ԭ���ǴӲ����Ķ�������������ġ����ң������Ǹ��ݲ����Ķ��壬�õ����ֵIJ����嵥֮�����Ƚ��з��࣬�����ƶ���ֹ��°��������ڲ�ȡ����Ȼ��������ĵ�һ����ǽ��������ķ���ϵͳ����û����������ֹ������������شӲ����嵥����������ֹ���������Ϊ����ֹ�����ƾ��������ġ�Ȼ�����ò�ֹ�������ȫ��������ʹ֮�������Ա���Ӧ�á� ȡ�룬�ͺ����ö������������⣬Ҫ���٣��ö��٣���֣��Ͳ������⣬Ҫʹ���еĺ��ֶ��ܲ����ijЩ���ֿ������ܺò�֣���Ҫ���һ���ַ��������к��֣�ȴ�������ס�������Ϊ����Ӧ��������ӣ�������Ϊ���Ӧ���������롣���ǣ��ھ���ִ���У�����һЩ���⡣��֣���һ����Ҫ��ԭ���ǣ�Ҫ�������ǵ���֪��������Ҫ����ѧϰ�������ϵĿɽ����ԡ� �е��˲����⺺�ֵIJ�����Զ��壬��˼ĺ��Ѱ�Ҳ�ֹ���֪�����˶���Ϳ�ʵ�ֲ�֡����Ǹ��뵽����ֱ�����Լ��������û����Լ�����������ͻ����ˡ���������ʻ����� �еIJ��������硰����ڡ������ߡ�ͤ�������У�����һĿ��Ȼ�ؿ����������ǿ��Գ���Ϊ�������ݴ˰ѡ��ġ����������в�Ϊ����V���͡�� ���������ױ����ǽ����ˡ� ���������ױ����ǽ����ˡ� �е��֣���������ġ��W���������û�����⡣������ġ��顱Ҳ������һ��ģ�����Ƶ�ʺܵͣ�û�а취�ӱ������õ�֤����Ҫ��Ҫ�����ǿ�����Ϊ���м�ġ� ����һ��Ʋ���������⣬�����ڰ�Χ���ϣ���һ����Χ�ṹ����Χ�ṹ�к�ǿ���ȹ��ԣ����ܲ�֡�����ġ� ����һ��Ʋ���������⣬�����ڰ�Χ���ϣ���һ����Χ�ṹ����Χ�ṹ�к�ǿ���ȹ��ԣ����ܲ�֡�����ġ� ����ճ���ṹ��������ͬ�Ļ����ṹ��������һ����������˱���� ����ճ���ṹ��������ͬ�Ļ����ṹ��������һ����������˱���� ������Ʋ��ΪʲôҪ��Ʋ����������ʼ����У�ճ���ڻ����ʻ��ṹ�Ķ��˻����Ͻǣ��������϶�ճ�������±ߡ����Ʋ�ʣ����������ʻ��ṹ�������ԣ�Ҳ�������Ͳ������������� �ܶ�����ѧ�Ҳ������ֵ�Ŀ�ģ�����ϣ�������ܵر���ԭ���Σ���ô������˶���֮�٣����������������������Ӳ�֡����ֲ�ֵ�Ŀ���������ڲ��ô�����������ʹ�ڶ�ĺ��ֵõ�����������ֶ�����ԭ���Σ��ǻ�Ҫʲô��֣���Ȼ˵�ǰѺ��ֲ��Ϊ�������ǾͲ���ԭ���Σ������б���ԭ���ε��������ϵIJ��������ԣ��ܲ�ֵľͱ��뾡����֡����˾��ò��Ʋ�ʵġ� ����Ϊ����ʵ�ڰ��ۣ����������̡��족��Ϊ��د��ľ���͡�د��δ��������������Ǿ���û���뵽�������������ô���ʹ�ô���ʹ���ǵõ�������ʵ����һ�ֱ���˼�������֡� ����Ϊ����ʵ�ڰ��ۣ����������̡��족��Ϊ��د��ľ���͡�د��δ��������������Ǿ���û���뵽�������������ô���ʹ�ô���ʹ���ǵõ�������ʵ����һ�ֱ���˼�������֡� �����ԡ��ꡱ����Ϊƫ�Ե��֣�һ����ʰ����������ṹ����һ��Ū�������֡�����Ϊ�ѡ����硰�ҡ�ꫡ��ɡ�갡��ȣ�ֻ���������ã����ܽ��������һ����˵���� ���߳���������������IJ����嵥����Ϊ��ϲ�������Ϊ�ģ�ȡ����ȫ����ϲ����������ˡ� ���͡� ���͡� ���������������ݱ�����ı��뷽����������ߣ�Ҫ��Ϊ��د���桢 ���������������ݱ�����ı��뷽����������ߣ�Ҫ��Ϊ��د���桢 ���������ϡ�������ȡ��Ĺ������롰�γɰ�Χ���𡱵Ĺ���ִ�������������Ʋ���Ȳ���Ȼ����һ�����������桱��ڶ���Ʋ�ʣ���������ӣ��γ���һ��ȫ��յ�����´��εİ�Χ�� ���������ϡ�������ȡ��Ĺ������롰�γɰ�Χ���𡱵Ĺ���ִ�������������Ʋ���Ȳ���Ȼ����һ�����������桱��ڶ���Ʋ�ʣ���������ӣ��γ���һ��ȫ��յ�����´��εİ�Χ�� ����ҲӦ��˵�Ǻ��ȹ̵ģ��ȷ��ϡ�������Ʋ��һ�ɲ�ԭ��Ҳ���ϡ��γɰ�Χ���𡱵Ĺ涨��������ѡ� ����ҲӦ��˵�Ǻ��ȹ̵ģ��ȷ��ϡ�������Ʋ��һ�ɲ�ԭ��Ҳ���ϡ��γɰ�Χ���𡱵Ĺ涨��������ѡ� ������Ϊ�� ������Ϊ�� �����������������κεط�֤����������������̺ᣬ����ԵĶ����ԡ���Ӧ�õĽǶ�����������ֻ�������硰�١��ڡ�Ͼ���ȼ��������õ���������Զճ��һ�����ǰ���Щ�ֺ�����Ϊ�ĸ������������Ƿ�Ϊ���������Υ����֪�����ġ� �����������������κεط�֤����������������̺ᣬ����ԵĶ����ԡ���Ӧ�õĽǶ�����������ֻ�������硰�١��ڡ�Ͼ���ȼ��������õ���������Զճ��һ�����ǰ���Щ�ֺ�����Ϊ�ĸ������������Ƿ�Ϊ���������Υ����֪�����ġ� ���������ֲ�����������˵����ô�����ݶ����ֺ��֣�ֻ�ܵõ��ٷ�֮��ʮ�����ϵIJ���������һЩ��Ҫ����Ӧ�õ���Ҫ�������о�������ȷ�����������硰�ڡ����������ס��ڡ���ؤ���桱�ȡ�����˵Ӧ�õ���Ҫ��������ԭ��һ�����ƻ����ֲ����Ľṹ���ɣ���Ҫ�����ܵؽ��ͼ�����������Ҫ�ʺ��ִ�Ӧ�á� �� ʮһ�������嵥��ÿ��������֤�� �����������������ֵIJ���Ǻ������ַ�����˳���ֵIJ��ʹ���ʶ������ֿ�6763�����ֻ����һ�ź���368���������嵥�����ǣ����Ų����嵥�е�ÿ�����������ʹ��ڵĺ����Ա���õ�֤�����ݴ��嵥����ȷ���� ���������������ԣ�һ��һ����֤�������ĺ����ԣ����Ը��õ����Ʋ����嵥����ʹ�����IJ����ʹ����и������۳ɷ֣�������ѧϰ�ͼ��䡣��ô���֤�����������ʹ��ڵĺ������أ� ������Ϊ������ƴ������ʱ��ȷʵ���������Լ�϶��ͬʱ�����ֿ��Ի���ij�ֻ����ʻ��ṹ���͡�����һ��ֱ��֤���ķ������������ǽ�����һ��������嵥����֤���� �ڱ������У���һ���� ���IJ��������Ǵӡ��ȡ����ұߵġ� ���IJ��������Ǵӡ��ȡ����ұߵġ� ��������ϵ�һ����ɵġ������������к��֣����硰�ȡ��ߡ������ڡ��ԡ������ȣ���û�з��֡������ԡ���Զ��������ڡ������붥�ϵ�һ�ᣬ��������һ�𣬴���û�зֿ�����������ѧϰ�������ϾͲ������ܡ��ο�������������ȡ��ֿ�������������������⣬�������֣�ȴ����ܵ���Ϣ��ģ���ÿ���ֶ������ĸ���������Ҫ��ȡ��ʱȥ��һЩ����������˵����ô����֣�����Ӱ����֪�����һ�������Ϣ��ģ����ô�����ˣ������������Ӧ�ûָ�����ԭ���ĺ�ʡ��е�����Ϊ�������ּܣ����ޡ�Ҳ���Ѷ��ϵĺ�ʲ������Ϊʲô�������ܲ�����Ϊ����Ϊ���ޡ�������ġ��̡����ڡ��ȡ��š�������������ʱ���Լ����������Ͻ����ܡ� ��������ϵ�һ����ɵġ������������к��֣����硰�ȡ��ߡ������ڡ��ԡ������ȣ���û�з��֡������ԡ���Զ��������ڡ������붥�ϵ�һ�ᣬ��������һ�𣬴���û�зֿ�����������ѧϰ�������ϾͲ������ܡ��ο�������������ȡ��ֿ�������������������⣬�������֣�ȴ����ܵ���Ϣ��ģ���ÿ���ֶ������ĸ���������Ҫ��ȡ��ʱȥ��һЩ����������˵����ô����֣�����Ӱ����֪�����һ�������Ϣ��ģ����ô�����ˣ������������Ӧ�ûָ�����ԭ���ĺ�ʡ��е�����Ϊ�������ּܣ����ޡ�Ҳ���Ѷ��ϵĺ�ʲ������Ϊʲô�������ܲ�����Ϊ����Ϊ���ޡ�������ġ��̡����ڡ��ȡ��š�������������ʱ���Լ����������Ͻ����ܡ� ���߲����˺ܶ����뷽��������ʹ�á��顱���ָ��������ȣ���Ϊ���뷽��������Ԫ�ģ����Dz������Լ�϶��ֵġ����Լ�϶����һĿ��Ȼ�ؿ�������������֤�����������ĺ����ԣ����������ǵ���֪�����������ಿ��ƴ�����֣���ʱ�����Լ�϶����ʱȴ���IJ���ճ����һ�����Լ�϶�Ĵ��ڲ�����֡����Ǻ��ֽṹ���ÿռ����Ҫ�����硰�ڡ��͡�ʮ����������������ƴ��ʱ��Ϊ��Ҷ������϶�����Եģ�������������ƴ��ʱ��Ϊ���š�����϶�Ͳ����ˡ����ڡ��͡�ʮ������������ģ����Dz�ͬ�ıʻ��ṹ�飻�в�ͬ�ıʻ����ơ����ֲ�ֵ��鷳����Ҫ��������ӵ����Լ�϶��ֻҪ�����ȡ����ˡ�һ�������Լ�϶�IJ����������ǵ����Լ�϶��֤�����ǵ����Լ�϶������һ���������Լ�϶�IJ����������ǵ����Լ�϶��֤�����ǵ����Լ�϶������һ���������Լ�϶�IJ�����������ʡ�����ˡ� ��������˼�룬�������֤��������Ϊ������ ��һ�����ѳ��ֲ������»��ֵ��еIJ��ף�ָ�����ʻ����ϵġ��顱�����С����ˡ������ݱ����о�����Щ���ֲ����Ͳ��ף����������Լ�϶�ģ��ڲ��ʱ�������֪��������Щ����ֻҪһ���嵥�Ϳ��ԡ� ���ֲ�����125���� һ���ҡ������ˡ���������С�����ġ��������������ס��ǡ�����ʮ�������š�إ���ʡ�����ئ���ᡢ�С��ᡢΤ���ꡢ�¡��������������ϡ�������������ذ���ߡ�ؿ��Ҳ���͡��硢����߮���ꡢꧡ�ҷ���ӡ��ݡ��ޡ��ڡ��������ա�Ի��Ŀ�������ҡ��ġ�����㡢ĸ��ʬ�������֡�����Ů���ߡ��ʡ��š������ˡ�ɽ������ϰ��Ϧ���ޡ������¡�����Ƚ���ˡ��롢�ˡ��ۡ�����Ƭ���ܡ����������㡢���ġ��롢�ɡ�ʷ������ľ��ĩ��δ�������硢���������������������桢خ�����������ɡ��ڡ��ס��ϡ�ֹ��ʿ�������ɡ��������������塢�� ���ף�44������ �R�������֡��ꡢ�ߡ��ݡ��]���ᡢ�^������ڥ����ꡢ�¡�ܳ���á������С�҂�����������ࡢ�⡢⺡�붡��ɡ��Ρ��硢ڢ��岡��W�� ���衢�桢 ���衢�桢 ���롢�ڡ��ȡ������̡������ࡢ�顢�� ���롢�ڡ��ȡ������̡������ࡢ�顢�� �ڶ�������������ֲ���������ƴ�������ߣ��������ǹ���ʱλ�ں��ֵ��м䣬û�б�ѡΪ���ף�������Ҳ�������Եļ�϶������һĿ��Ȼ�ؿ��������ڲ��ʱҲ��������֪����Щ������Ҫ�ٳ�һЩ������֤�����еIJ������硰�������ڡ��١����У������Լ�϶���õ���֤�������ǰѡ��ѡ��ֲ�Ϊ�����]�����������Ͼ������ܡ�����û�а취֤�������ں���������Զ����ġ������Լ�϶�ģ�������ǰѼ����ѡ��ȡ����Բ�֣������ϾͲ������ܡ� �����Լ�϶�IJ�����149������ �� 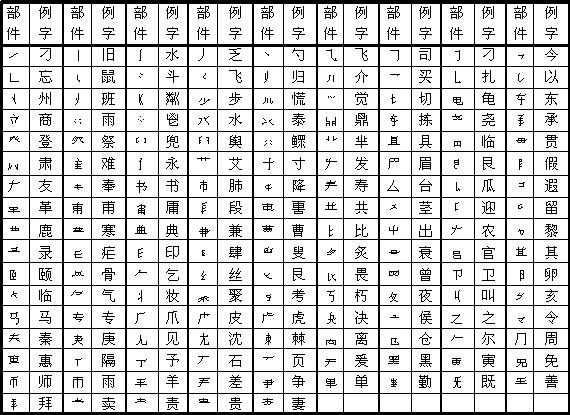
���һ�������µ�һ���������Լ�϶�IJ���50����֤����һ�������ķ�������������ı����ڼ�϶�����ɷ�Ϊ����1������Ʋ�ʲ���2����ͬ�ıʻ����ƣ���3������ֲ��������ǵı�����ӣ���4��������ͬ�ıʻ��ṹ����5�����ꡱ���ಿ���ĺ���������á� 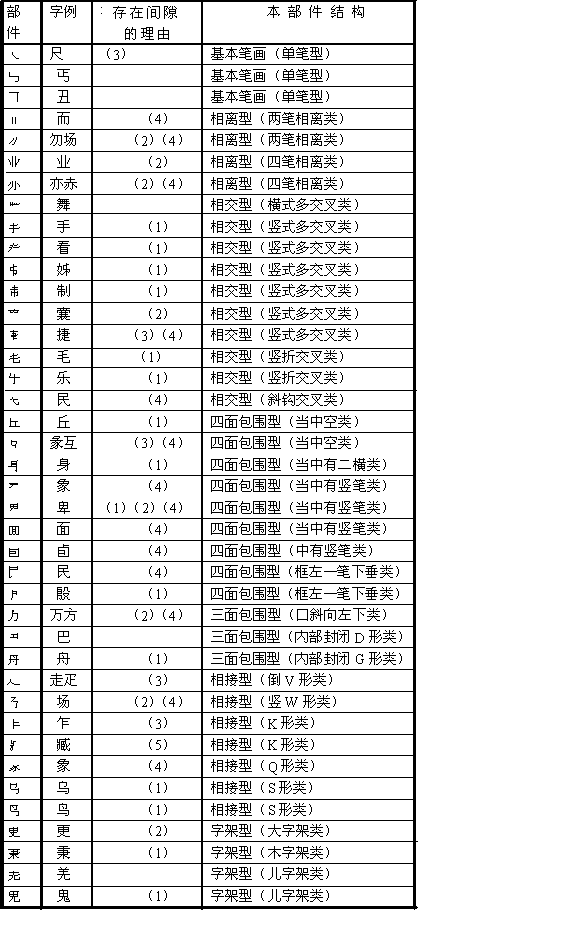
�������Ϸ�����368���������ֹ鲢Ϊ352������ֻ�С��� �� �� �� �� ��������������õ�֤�������������ǵ��ʲ�����������ƴ����ؤ���ơ������֡��÷�֤��֤���������Ǵ����ż�϶�ģ�����Ҫ˵��ֻ�ж�ʿ鲿����������֤�����ʲ�����������֤������Ϊ�������Dz�����������֮ƴ����ؤ�����ʿ����˲����ֻ�С�����������һ�����ᣬ���ԡ��衢Ǽ���͡����Լ���������ƴ�����֣��硰Ť��ť���֡��ʡ��ѡ������ȣ���ô�죿Ҫ����Ϊ�涨���Ҹ��˵�����ǡ��������һ��Ӧ������������ڷ����ཻ�͡�ͬʱ������Ҳ�����ڲ�֣�������Ϊһ�����������߲�Ϊ�� ��������������õ�֤�������������ǵ��ʲ�����������ƴ����ؤ���ơ������֡��÷�֤��֤���������Ǵ����ż�϶�ģ�����Ҫ˵��ֻ�ж�ʿ鲿����������֤�����ʲ�����������֤������Ϊ�������Dz�����������֮ƴ����ؤ�����ʿ����˲����ֻ�С�����������һ�����ᣬ���ԡ��衢Ǽ���͡����Լ���������ƴ�����֣��硰Ť��ť���֡��ʡ��ѡ������ȣ���ô�죿Ҫ����Ϊ�涨���Ҹ��˵�����ǡ��������һ��Ӧ������������ڷ����ཻ�͡�ͬʱ������Ҳ�����ڲ�֣�������Ϊһ�����������߲�Ϊ�� ���Q���������������͡����Բ�Ϊ�����]���������������������� ���Q���������������͡����Բ�Ϊ�����]���������������������� ���ڣ������Ѿ��ѱ������嵥�е�368���������ֹ鲢Ϊ352����֤����ϡ������嵥����ƴ�����������ֿ�6763�����֡�������ּ��������ǻ������������������IJ������壬���������IJ�������Ϊ�κ�һ���²��������벻���°���������������ֻ����ʻ��ṹ���ͺͱ��������е�48����������ˣ������������Ը�����֪��δ֪�����к��֡����Dz���˺���20902�����ֵ�GB13000.1�ַ�����ֻҪ����68���²������Ϳ���ƴ���������еĺ��֡� �����̵���Ҳ������˵����352����������̫�࣬�������ֻ����125����ʵ��ʹ����199�����������Dz�֪����125������֮352��ʹ�õļ������ߵöࡣΪʲô�������ڷ����������͵�һ��һλ�С�������ͷ���һ�������к��������f��ꧡ��塢һ�����ں����У�����������ָ����ʹ�һ��һλ��������ڡ�����ƴ����ĸϵͳ���У�����������ıʻ�����14���������������� ��������������14�������Ϳ��Դ�B��������ѧ�г������ķ���Ϊ�����ϡ������Ǵ�������ԶԱȣ�˭�����ϡ��úã���������ͷ���һ��û�аѡ������f��ꧡ��塢һ������ָ���Ϊһ����ĵ�������������ǿ���һ��һλ�������������Ծ��������ָ��һ���ʻ��Ǻ�ʣ��ڶ����ʻ����Ǻ�ʣ�����һ��һλ������������һ�����⣺Ϊʲô�ָ���ͷ������ʳ�һ��һλ���ֱ������������λ��ԭ��Ȼ�����������⡰�����f��ꧡ��塢һ������ָ������Dz��Ծ������еġ��塱���ڶ����ʻ����Ǻ�ʣ����еġ�һ����û�о������ʻ�����������ֻ������Ӳ����������������������14������������������ıʻ�����һ�仰�ͽ��������װ��ˣ�û���κ����壬��Ȼ������ָ��üǡ�������Ϊʲô������B����������Ϊ����ıʻ���С������������ĸ�������������ģ����ϵ�����ʣ���������ࡣ�� ��ABCDE�������롰һ�������塱�����Ӧ���ͱ��ڼ��䡣��һ��һλ���ñʻ�תΪ���֣���תΪ���̷��ţ���������ѵöࡣ���ԣ�����352�����ֱ�125������˵��˵�࣬�Dz���˵������ġ� ��������������14�������Ϳ��Դ�B��������ѧ�г������ķ���Ϊ�����ϡ������Ǵ�������ԶԱȣ�˭�����ϡ��úã���������ͷ���һ��û�аѡ������f��ꧡ��塢һ������ָ���Ϊһ����ĵ�������������ǿ���һ��һλ�������������Ծ��������ָ��һ���ʻ��Ǻ�ʣ��ڶ����ʻ����Ǻ�ʣ�����һ��һλ������������һ�����⣺Ϊʲô�ָ���ͷ������ʳ�һ��һλ���ֱ������������λ��ԭ��Ȼ�����������⡰�����f��ꧡ��塢һ������ָ������Dz��Ծ������еġ��塱���ڶ����ʻ����Ǻ�ʣ����еġ�һ����û�о������ʻ�����������ֻ������Ӳ����������������������14������������������ıʻ�����һ�仰�ͽ��������װ��ˣ�û���κ����壬��Ȼ������ָ��üǡ�������Ϊʲô������B����������Ϊ����ıʻ���С������������ĸ�������������ģ����ϵ�����ʣ���������ࡣ�� ��ABCDE�������롰һ�������塱�����Ӧ���ͱ��ڼ��䡣��һ��һλ���ñʻ�תΪ���֣���תΪ���̷��ţ���������ѵöࡣ���ԣ�����352�����ֱ�125������˵��˵�࣬�Dz���˵������ġ� �� δ�����һҳ �� | 


