点评时间
本来以为看完这两篇博士学位论文要2天呢,结果就用了2个小时。:D《基于拓扑学和统计学的无字库汉字智能造字研究》,所谓的拓扑就是字根之间的关系,所谓的统计就是众多字根的分布。这篇学位论文基本上就是再次提出了那种妇孺皆知的输入法方案――IDS,增加了一点点扩充。看这篇论文,感觉很熟悉、很亲切。:cry: 这篇论文其实并没有什么学术独创性,但看在辛苦的折腾了GB18030-2005 七千多个汉字的份上,也算有点成果。对搞字根输入法的坛友,也许还有点参考价值。
《认知模式识别理论及无字库智能造字研究》,像是2篇独立的硕士学问论文粘到了一起。一部分讲了如何利用图像处理的仿射技术提取字根,一部分讲了怎么做可以带有预测功能的输入法。两者之间没有联系。给人的感觉有点凌乱。:( 这篇论文不仅没有研究独创性,而且所做的工作也没有深度,怎么看都像是10几年前的东西。坦率的说,水分太大。
再次感谢客串先生友情提供这两篇论文!向我们展示了国内学界对于汉字字形编码的一些实际工作。发现了不足,才好继续提高!
终结符和空结构
终结符用#表示,空结构用O表示。两个的作用不同。O是拓扑元集中的一个元素,任何引用O的操作返回一个空白。#是为了终结某一个迭代操作,引用#则使用元操作本身的线条。
比如 二(o,o)我们会得到一篇空白。二(o,#)我们会得到一横,二(#,#)我们会得到两横,在这种情况下,也可以省略括号和括号内的输入。
(七)一点图像处理
一直都在说拓扑元集的构想,现在想简单谈谈图像处理。首先,不要搞混图形(graph)和图像(image):从汉字结构生成适量字库并动态显示,或者根据拓扑员和基因型生成表现型,这些是图形处理。图像处理谈的是如何提取字根,做模式识别,以及进行基于图像的加密,等等。
提取字根是个费时间的事情。因为涉及到很复杂、也很费时的数学计算。但是,核心概念却很简单,就是比较,做遍历搜索。用数学语言说,就是计算两个对象的卷积。一般会做频谱变换,借以得到图像的某些特性。学生学习这些变换,wavelet是一个不错开始,然后再通过学习curvelet启发多尺度、多属性变换的思想。最终,根据不同的应用,建立自己独特的卷积核(kernel),或者独创某种分析卷积的方法。
在汉字图像处理上,一定要紧密结合汉字独有的字形结构特点。这个是所有分析的基准。把汉字作为一个普通图像泛泛的分析,得到的也只能是泛泛的结果。
[ 本帖最后由 jr0jr 于 2011-5-8 07:06 编辑 ] 我对《认知模式识别理论及无字库智能造字研究》这篇文章颇有微辞,可能和我自己的专业背景有关。作者使用了pso去优化sift,使用了dag去预测。如果我是答辩考官,我会直接问他为什么用sift,为什么用pso,为什么用dag?和其它哪些方法做对比了?实验证实了预测没有?……完全没有在论文中体现出来。
我可以理解,研究汉字很不容易,很费时间和精力,所以我不想评论作者本人。但是一个博士生的课题研究做成这样,指导老师有不可推卸的责任啊,唉:z: :z: :z:
[ 本帖最后由 jr0jr 于 2011-5-8 08:20 编辑 ]
遐思
说道核方法(kernel methods),我早就有一种感觉,纯拓扑析构的拓扑元,其实可以看作是一些核。基于核方法的空间频谱变换是使用各种核,从各个尺度上来搜索特征信息;而拓扑码在析构汉字的时候,是使用拓扑元,从各个尺度上寻找相似度,大到字形,小到笔划。两者有异曲同工的妙处。结合63楼最后一句话,基于拓扑元的频谱分析,应该是发掘汉字特征的一条有别于其它图像处理的路。
[ 本帖最后由 jr0jr 于 2011-5-8 08:25 编辑 ] 感觉你的研究希望不大。
汉字库体系庞大,字体繁多,不同字体其拓扑特征差异很大,用你那二十个字母,能生成各种字体?
就算是只以宋体或者楷体为唯一处理对象,那八万汉字都够呛。
何必要析构七八千汉字呢?山人全息输入法的300字根或者部颁560部件集能弄下来就不错了。字根集或者部件集能搞定,再大数目的汉字集也不在话下了。 汉字的拓扑构型信息用于OCR,我是支持的,因为目前的OCR几乎不利用这方面的信息,而这种信息往往具备较大的汉字特征区别信息,且冗余度较低。
[ 本帖最后由 谢振斌 于 2011-5-8 15:29 编辑 ] 原帖由 客串客串 于 2011-5-8 10:44 发表 http://www.pkucn.com/images/common/back.gif
感觉你的研究希望不大。
汉字库体系庞大,字体繁多,不同字体其拓扑特征差异很大,用你那二十个字母,能生成各种字体?
就算是只以宋体或者楷体为唯一处理对象,那八万汉字都够呛。
何必要析构七八千汉字呢?山人 ...
谢谢客串先生的担心啦~~:loveliness:
不过我们不会做输入法,不去生成各种字体。这些事情都和我无关,那是别人家的事情。
这个主题贴里,我用了1楼,15楼,18楼,42楼,44楼,48楼 一直不断得再重复这个主旨:
提出拓扑码这个想法,是为了从汉字结构体上分析它的信息承载能力,绝不是为了做成某种构字的输入法,和IDS,CDL的宗旨完全无关。通过这次研究,我们希望可以看到汉字在字形结构上的特点,尤其是在信息化的时代,发现旧汉字的一些桎梏。希望可以给不断演变的汉字字形体系,带来一点基于具体实验的参考资料。 原帖由 谢振斌 于 2011-5-8 15:27 发表 http://www.pkucn.com/images/common/back.gif
汉字的拓扑构型信息用于OCR,我是支持的,因为目前的OCR几乎不利用这方面的信息,而这种信息往往具备较大的汉字特征区别信息,且冗余度较低。
是的,OCR应该是潜在应用之一。再配之以一个语义推断系统,让大部分识别工作在大尺度下完成,提高速度。
(八)原始动机
这个论坛上一直有人在比较汉字在信息承载方面的优劣势。大家拿出社会科学范畴内的资料进行论证,但是几乎没有人拿出工学实验结果。泛泛地说,一个二维图像,点线少了,无法在有限的空间内把诸多不同的个体区分开,点线太多了,又不利于识别。点线的密度和排列决定了汉字信息是否被合理承载(这个和那些讨论编码长度的信息绝无相关)。
50年的简化字进程中,似乎并未有人真正定量的分析过汉字字形拓扑对信息承载的影响。这才是本主题所关心的话题。不管是文改也好,文守也好,希望展开对话的时候不要想当然,要凭着真实的数据说话! 楼主倡导汉字结构拓扑研究,从感性的认识到理性的思维,玩的可不是“形而上”,比我高明得多。:) 原帖由 yywzw05 于 2011-5-8 20:30 发表 http://pkucn.com/images/common/back.gif
楼主倡导汉字结构拓扑研究,从感性的认识到理性的思维,玩的可不是“形而上”,比我高明得多。:)
别装谦虚:loveliness:
没有“串”字那一竖的启发,哪有这些劳什子。
一点反思
当老大帝国的酸儒们穷尽半生苦练书法的时候,不列颠的坚船利炮就来了,砸碎了夜郎的酣梦。:( 萌醒过来的酸儒们产生了全面拉丁化的冲动。可人们需要的是全盘拉丁化么?还是对汉字的认知的转变呢?从繁体字到简体字究竟有没有体现酸儒的觉醒程度呢?第一,粗鲁地归并是科学的么?这个已经被无数次证实,是不计后果、盲目愚蠢的。
第二,有保存毛笔书写习惯必要么?书写是为了记录语言思维,只要能被辨识,书写的目的就达到了。美观是第二层,美观还会被新时代赋予新的含义。毛笔字的时代早就过去了,钢笔字的时代也许都即将要结束了。与其苦练手书,我们是不是该选择去美化符合认知心理学的计算机字体呢。使国人看得快、看得准,是不是才是我们最终的目的呢?
对现有汉字字形的评价,还是应该由数据说了算。从工程技术角度研究汉字,不是这个意思么?
[ 本帖最后由 jr0jr 于 2011-5-9 04:48 编辑 ] 也许我们低估了老祖宗的智慧
三分法则 井田理念 要重新认识
原帖由 jr0jr 于 2011-5-7 20:32 发表 http://www.pkucn.com/images/common/back.gif
wangs先生,如果发现拓扑码的表现型不能区分某些汉字的时候,那就反映了,某些汉字需要进行修改。比如,曰就最好进行一点形体变化。
您提到和汉语拼音类似,那您想类比的点在哪里?我没有理解。我需要您再说的 ...
本来是不能区分,后来标准中就把曰字改了(中间一横不到头)。但改字是要有依据的,至少历史上出现过这个字型,并且有一定的认可程度。汉字是人类文化的一部分,不依赖于任合工具和算法,计算机和各种算法是为汉字服务的,要服从汉字的历史和规律,而不是汉字服从计算机或某种算法。
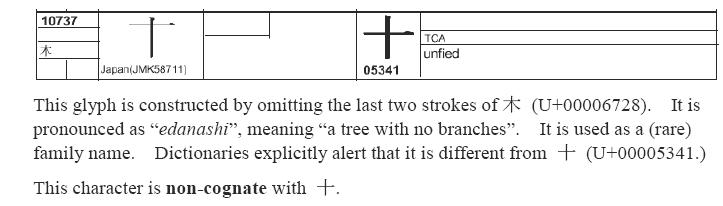
看看日本的这个字,拓扑上与十怎么区分?