�� ���ӹ�������� �� ����� �� ��ժ Ҫ�����ļ�������ı����Ƕ�Ԥ���ڵ����е������ַ������ϵļ����������ԭ���Ͳ������̶����Ű�ļ��ַ���ͬ�����ֱ�����������ַ������ϵIJ���˳��ͱ�š����ڱ������������ƽ��ÿ�����ֻ������ڶ������£����ܻ�����ʵ�ֺ�ƽ��ÿ�ֵĻ�����������1.5�����¡����ϲ��������������Ǻ��ֱ���������������������Ϊ��ʵ�������еı����ṩ����� һ���������������Դ�ڱ��� ����ĺ��ֱ�����ָ��ȷ�����ַ����������֮����Щ�ַ��������ӹ������桢������ת��������ȸ�����ҵ�ļ�����ô��롣����ĺ��ֱ���ֻ��ָ�˻�����ʱʹ�õIJ����롣�������Ƶĺ��ֱ���רָ�����롣 �ӵ���ͼ�Ĵ�����ԭ�������������ַ�������ͼ����ʽ�������ֻ��ķ��������ڵ����еġ��Ե�����˵���������һ�������ַ���һ�������ַ���ԭ������ȫ��ͬ�ģ���������֮�֣������ڲ�������˵������������IJ��ȴʮ�����ԡ������ַ����٣�ͨ������£����������Dz���Ҫ����ģ������ַ���״���ӣ������Ӵ�ֻ�ܱ������롣������벻�����������������⣬��ʹ��������ѧϰ���ա���������ʱʮ��ͷ�ۡ�ʱ�����գ���������ĺ��ֱ�����δʵ�֣�ʹ����������϶������������뷽���ݡ���һ���Դ�����ʷ���Ľ��ۣ��ƺ������˻���������Ľ�����ɡ�������Ȼ�Ǻ��ֱ����ҵ�మ���ߣ����Դ˽���ʵ�ڲ��ҹ�ͬ�� ���ļ�������ı��ʣ��Ƕ�Ԥ���ڵ����е������ַ������ϵļ������ֿ��������û����ķ�ʽ�����ñ�д�֣���ʵ������Ȼ����������IJ���ԭ���Ͳ���������Ǧ���Ű�ļ��ַ���ͬ��ֻ�ǵ��Դ����˴��Ǧ������ľ�ܺ����̡����֪�������ֹ������Ű����ʱ��������һ��һ���ؼ�ȡǦ�ֵģ����ǵ��֡�������顢�̾������û�ϼ�ȡ�ġ���������Ҳ�ǰѵ��֡�������顢�̾�ͳһ������룬��ϴ�ȡ�ġ�����ʹ��Ƶ�ʵIJ�ͬ��Ǧ�ּ�������Ҫ���ϼ�������ʮ���������ٸ���ͬ�ĵ��ֻ����ڵ���������ǵ��ֻ��Ǵ��ÿ����ֻҪ����һ��������ȡ֮���������ֹ��˼���ʱ���ռ����Ӽ�ʮ�������ײ��ȣ�ȡ��ʱ��ϳ�����������ֻҪ���ڵ���ǰ������ָ�������С���ǰһ�����ֹ���ÿСʱ����1000-2000�֣��������ڹ����Ƚ��ˣ�ʱ�վ��������ˣ�����Ч�����һ����ÿСʱ��������2000-4000�֣�ÿ���Ӵ�Լ30-60���֡����������̶ȵ���ߣ�����������γɣ�Ч�ʻ�����ߣ�ÿ��������50-100�֣�Ӧ����ϡ��ƽ�����¡� �ӻ������������㣬����Ҳ�ܵó���ͬ������������ֵı������룬��Լƽ��3����������һ�����֣�����Ѵʺʹ���Ҳ�������룬ƽ���������ҿ�����һ�����֣�����ٰ�ר�ô���ͳ��ö�����ͬ������һ��������룬��ƽ������һ�����ֵ��ڶ������¡����ǵ�һ�����ִ�Լ��3.7��Ӣ����ĸ���ص���Ϣ���൱�������������������ľͲ�����Ӣ�ġ������Ǿ����ҳ���Ӧ���ַ��Ͷ���ܲ����ף���Ҳ����ƺ�����ʹ�ú��ֱ�����������ڡ� ���ڱ�����������������ر���Ҫ�����壬������Ʒ������Ĺ��ɵģ��֡��ʡ���ͳһ�ģ��������ĵ�ѧϰ��ʹ������һ��ģ���ѧ����������������룬�ų�Ϊ������������ר�ҡ������ר�Һ��ҵ�మ����Ϊ֮���Ľ��ǣ��������Ŀ�ꡣ������߶������һ�����������������������ַ����ܱ����������������������ַ�����ʹ����������ϲ��������������� ������ȷ�������룬����������� ��������һֱ�����ű�������ߵ����⡣�������ز����ߵ����������Ͳ������������������ٶȣ�����һ���˶��Է�̬�ȶԴ����룬�����������ʵĸߵͣ���Ϊ���ۺ��ֱ�����������뷨���ӵ�һ����Ҫ�������ֹ۵�����ȫ����ġ� ��ѧ��˵������������Եĺ��ֱ����뺺���ڵ�����Ļ�������һһ��Ӧ�ģ���������Dz����ʵģ���˺��ֱ��뱾������û�������������ģ�����DZ���ĵ����ԡ���ô��������ôһ�����أ�����˵���������ָһ�������Ӧ������֡������룬һ��������ô�ܶ�Ӧ��������أ���ô��������Щ�����أ��ش�˵����������������ǡ������룬��Ȼ������Ű����Ƿֿ��ˣ���ô����˵�������أ�����ѵ������DZ����һ������Ϊ�ˣ����߶��������һ�����壺��������������ֵı��뼯��Ϊ���뼯�ϣ����ڱ��뻥Ϊ���롣�����������������Ŀǰ���еĺ��ֱ��뷽������������ģ�ֻ����������س̶Ȳ�ͬ���ѣ����б���Ϊ��߱��뵥���Եĵ籨�����λ�룬��ʵ�����������صģ����Ǹ���һ�������룬����ֻ������������֣���˱���Ϊ�����롣ϰ���ϳ�Ϊ��������������ַ������������ù������Ժ��������֣���������������ֵġ����е��������ж������������ijɷ֡� �����������ʱ��������һ����Ժ��ֽ������ɴη��ࣻҲ�����ü�����Ժ��ֽ������ɴη��ࣻһ������Էdz���Ҳ���Էdz����ӣ������ù���������˽������ͨ�ڡ���Ҳ�����С�����������ͱ�ͨ������֮ȫƾ����ߵ���Ǻ涨��ֻ������ܻ��в��ֺ�����ֻ����������ֵġ����DZ����ֶ�������ĵڶ��ֶ��壺���Թ���Ժ��ֽ���������ʱ�����ϸù�����ַ����������飬���ڵ��ַ���Ϊ���롣����������壬�ڻ�����������һ��֮ǰ����������룩���������κα��붼��������ı��룬����Ϊһ�������飬���������飬����������......�����ԣ���ͬһ���뷽���У��������������ƽ��ÿ���������ɷ��ȡ����ŷּ����������ӣ������������������ֵ��ƽ��ÿ�����������������1�� ���Ƕ�����������ȷ�����⣬����������Ϊ���������ˡ��ٶ���һ���൱��ѧ�ı��뷽������������4����룬��������1%���¡����������������������ױ������һ���൱���ѣ���ÿ�����ֽ����Ĵ����Ҳһ���൱�鷳������涨��4�벻��������룬������ű��룬��ʱ�����ʿ��ܻ�������20%���ң�����涨��3��Ҳ����ű��룬�����ʿ��ܻ�������98%���ϣ�����ÿ�鶼�����롣����������Ϊ���뷢���ʱ���и�ר�������˵�����������������㴦������ֻҪÿ���ּ�ס��������ˣ����룬������һ�����˫�ֱ�ʾ��ӭ�ġ� �ѱ�Ӧ�ɲ��������ǵ������ר����ͻ�����������������ܻ�������ʵ�ʣ���Ȼ���ܻ��������������Զ�����봦�����ӡ����ܻ������������ר��������ר���Ǹ�������������⡢���õ��ص������Ƴ����ģ��������������Զ�������ƥ�䡢������һ�������һ�����������ͻ��Զ�������ֱ����ɡ����ܻ����뷽���Ƕ����ڸ��ֺ��ֱ��뷽���ָ��ڸ��ֱ��뷽���ģ��������ڳ���λ�롢�籨��֮����κα��롣���Ǻ����Ļ��������Ļ���ϵ����㷶�������������������о�����ȷ������ǿ������ܻ����뷽����ʵ�֣���ʹ�����ߵĹ���ǿ�ȣ��ر�������ѹ������ͣ�����Ч�ʴ����ߣ�ƽ�����������ɽ���1.5�����¡�����˵����ͨ������£����������Dz���Ҫ���ܻ����뷽���ģ���ֻ��һ��һ����ĸ�����룬�ٴ�һ�������С����ĵ��ޱ������������������߷dz���Ľ�����ĵ����ܻ�����Ҳһ����������������ʮ�ֶʼɣ�����ν�����ɧ����;ͬ�顣 �����ᵽֻҪ�������ס��������ˣ�ΪʲôֻҪ��ס����������أ����Dzο�ƴ����ó��Ľ��ۡ�ȫƴ��ÿ���������٣�������ࣶ����ƽ�������������Ǽ�����ʵ�ʶ������ϣ������������Ϊ400�����ҡ�Ŀǰ���ܻ����뷽���������ϵ��൱�ã�ת����������98%���ϡ�������ƵĶ����룬�����鵱��600�����ϣ����������ת�������ʡ���Ȼ�������ѵ���ʶ�����������ܻ�������Ƶ��ж�ã�ת�����������ж�ߣ���Ҫ���˹���Ԥ���˹�ѡ���DZز����ٵġ� �����ǰѴ�����������⽻��ר�������ȥ����ʱ�����������ߵ�����Ҳ���Ӽ���ȷ�ˣ�Ŭ��Ϊ�������һ���ռ��Ͷ����롣 ������Ϣʱ�������������ĸ��ºͻ����� ����ö������������к��ֽ��з�������أ����ԴӺ��ֵ������ص������ǣ������DZ���ͼ�����֣�ÿ�����ֶ��������Ρ���Ľ���塣�����Զ�����һ�룬����ϳ�һ�롣�Ѻ��ֵ�����Ϊһ�룬ֻҪ�Ѻ��ֺ���ƴ���ĵ�һ����ĸ��Ϊ��������ˣ����������ֹ���23�����롣��������Ϊһ�룬���ǰѺ��ֵIJ�����Ϊһ�롣���ѵ��Dz�����189����ȫ����ס�ܲ����ס��취�ǰ�189�������ٽ���һ��������࣬��������ϲ�Ϊ�������ٵ����룬������ĸ�����������룬�������������ˡ������ǻ������189��������ij��ԣ� ��1����������������� ��λ | ���� | ���β��� | ��λ | ���� | ���β��� | �� | ���� | �� �� ʬ | �� | Ů�� | Ů �� | �� | ���� | �� ҳ | �� | �ղ� | �� Ի | �� | �ݲ� | ܳ | �� | �ܲ� | �� �� �� | �� | �Ʋ� | �� �� | �� | �벿 | �¹ţ������ | �� | ���� | �� ��� | �� | �鲿 | �� �� | �� | ���� | ʳ����� | �� | �ֲ� | �� �� | �� | �Dz� | �ڢѨ�� | �� | ���� | �� ɽ ʿ | �� | �̲� | �� �� | �� | �㲿 | �� �� �� | �� | ˿�� | �� �� ���� | �� | �²� | �� �� | �� | �� | �Ľ��� �� | �� | ���� | �� �� ʯ | �� | �ڲ� | �� | �� | �IJ� | �� �� | �� | ���� | ˮ �� | �� | �Բ� | ڥ�� | �� | ľ�� | ľ | �� | ֮�� | ��֮���� |
��2����������������� ��λ | ���� | ˵ �� | �� �� | �� | ͷ�� | ��ͺ����� | �� | �� | �Ჿ | �ᡢ���Ϲ���б�ҹ� | һ һ | �� | ���� | ����Ʋ������ | ح د �| | �� | �㲿 | �㡢�ࡢС���μ������ | ؼ �T С | �� | �沿 | ���ʽ��� | �� �� | �� | �岿 | һ���ݴ����ʻ��������� | �� �� | �� | ���� | �Ľ�����ķ��� | �� Ŀ �� | �� | �Dz� | ��������γɵĽ��� | �� �� �� | �� | �˲� | �˼������ | �� �� �� �R �R |
���ǿھ���һ����������� �IJ���巽���� �߽ǰ˰˼����� �����к����ͷ �������빲26��������������ʮ�����Ե�60������ף��ú���ƴ����26����ĸ��Ϊ���룬ÿ�����붼��һ���������ƣ�����ѧҲ���ǡ���������ֻ�б����������ޱ������á���Щ������Ȼ��������189�����ף���ʵ�����������ˡ��ĽǺ��롱���ַ���ʮ�ֱ��Σ����Ըɴ��Ϊ�������롣9���������뺭����120������ף�ѧϰ�ͼ��������������ࡣ���������Ĺ���ϲ���ֻҪ�����һ���ı����������ˡ����������������£� �����������루35�飩 �����ں����ϡ��¡����ҡ����Ͻ������λ����������ģ�ȡ�������������롣(26�����1)���������λ����������ģ�ȡ�������Ͻǵ���������Ϊ���롣(9�����2) �����������ֵڶ��������롣�����Ǻ��ֺ���ƴ���ĵ�һ����ĸ�� ��������Ƨ�ֵڶ�������������(9��)��������������������� ��1����������������ģ��ڶ�����ȡ����ȥ�����������ʣ�ಿ�����Ͻǵ��������롣 ��2����������������ģ��ڶ�����ȡ�������½ǵ��������롣 ��3�������ַ����еIJ��������磺�ߡ�ڥ���ġ������ȵȣ��ڶ��� ��Ϊ�� ���ģ����ִ���ı��������������Ӹ������롣 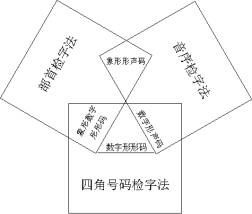 ���ֵĶ�дϵͳ��һ��ʮ���Ӵ��ϵͳ�����������ֵ������塢�����������д���ߡ��������塢��ѧ��������ϵͳ�������ϵͳ����������ξ����Ļ��ķ�չ����ѭ�Ÿ���㡢����Ч�������á����ռ��Ĺ����ڷ�չ��������Ϣʱ���Ժ��ֵ���д���ߡ����塢�����ֶ��ַ����˸����Եı仯�����ļ������뽫��Ϊ���˱���߱��Ļ����Ļ���������ܡ�������Ϊ���ڲ��������������Ρ�������Ļ�������ǰ���£��Ժ��ֵIJ����Թ���ϲ���������ĸ�����������룬����ʹ���ָ������ڴ�������͵������롣��ܿ�����һ�������á��������ռ��������ĸ��¡�������ֺ���������Сѧ���꼶��ѧϰ���գ���Ϊ�����Ļ�����������Ͳ�����Ҫ�����ˡ���ʱ���������붨�ܸ��ϲ������������롣 ���ֵĶ�дϵͳ��һ��ʮ���Ӵ��ϵͳ�����������ֵ������塢�����������д���ߡ��������塢��ѧ��������ϵͳ�������ϵͳ����������ξ����Ļ��ķ�չ����ѭ�Ÿ���㡢����Ч�������á����ռ��Ĺ����ڷ�չ��������Ϣʱ���Ժ��ֵ���д���ߡ����塢�����ֶ��ַ����˸����Եı仯�����ļ������뽫��Ϊ���˱���߱��Ļ����Ļ���������ܡ�������Ϊ���ڲ��������������Ρ�������Ļ�������ǰ���£��Ժ��ֵIJ����Թ���ϲ���������ĸ�����������룬����ʹ���ָ������ڴ�������͵������롣��ܿ�����һ�������á��������ռ��������ĸ��¡�������ֺ���������Сѧ���꼶��ѧϰ���գ���Ϊ�����Ļ�����������Ͳ�����Ҫ�����ˡ���ʱ���������붨�ܸ��ϲ������������롣
�ġ�����˵�� �������Ǽ����ס��ĽǺ��롢�������ֺ��ּ������ŵ���һ���Ķ����롣�������ԭ�����£� ��ͼ���������ηֱ��ʾ���ֺ��ּ��������ص��IJ������µļ����������������������������Ƨ������������������ִ�����������Ӹ�������������������������˹�ѡ�� 2��������������Ϊ��������Ϊ�����ö������֡�ѡ�������ķ�����ʵ���˶����к��ֵĶ�����ࡣ��GB2312-80���ڣ���������748�飬������312�飬��1060�����롣ռ��̬��Ƶ������99.5%���ϵij����ֿ����������������Ƨ�ֵ����������ж��٣��ϼ�ֻռ��̬��Ƶ������0.5%���������������ɻ��������������˳���������죬��Ƨ���ҵõ��������ศ��ɣ����������� 3������������֡��ʡ���ͳһ��N+1������ʽ���롣���ֶ��������ִ����������ִ��ļ���������36��һ���֣�����ĵ�һ���֡���Ϊ���룬���ո�����������˹�ѡ�������£�ƽ��ÿ�����ֻ������Լ1.7��������ѡ�������ʵ�����ܻ�����ѡ�����ƽ��ÿ����1.5�����¡����������Խ�ߣ���������Խ�١��� 4����������������ͱ������������ߵĸ��˹۵㣬�ܱ����Ļ�������ѧʶ�����ƣ����������������������������ƣ���©�ͻ���֮���������⣬������λͬ���������У����ߴͽ̡� �ο����ף� �����ֱ��뷽����ࡷ��ѧ�������׳�����1980��3�³��� ���ִ��������Ϣ�ʵ估�������������е����á������롢��ѧ��96��11�±���ѧ�����ļ� | 


