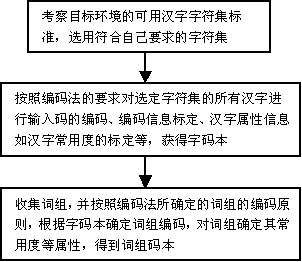
Ŀǰ���������뷽�����ֶ�������д���뼰���������Ѵ�ʵ���ҽν�����ʵ�ã�Ȼ������Ȼ����ķ��������䱾��Ӳ���������������Ҫ����Ȼ���ܳ�Ϊ�������뷨����������������ķ�������Ȼ��Ҫ���ú��ֱ������뷨����ͨ�����뺺�ֵĶ�Ӧ������ﵽ���뺺�ֵ�Ŀ�ġ�
���ǿ��Խ��������뷽����Ϊ�������룬������������������룬ͨ�������뷨���ṩ������ʹ��������ֹ��ܡ��������������뷨������Ҫ������������Ķ����뱾��Ϊ��������ʵ��ϵͳ�У�һ�����һ��ѹ�������ִʶ��ն������ļ��������Ҫ�ɼ����������Ժ��ֽ��б��룬������ϵͳ�ṩ��ȷ�����ϽṹҪ����뱾��ͬʱ��Ϊ�����뷨�ܱ��㷺ʹ�ã�ͬ�ڿ��������ڸ�����ѧ���ֵ�������Ӧ�������У�Ҳ����Ҫʹ�õ��뱾�IJ��ֻ�ȫ�����ݡ�
Ŀǰ���������뷨��ʹ��������Ҫ�ǻ�����������˴�½��̨�塢��۵ȵأ������¼��¼�ɢ������������Ļ��˾۾�������Ҫ���õĺ����ַ����ı��У���½�����õ�gb2312�����ַ�����gbk�ַ����Լ�̨�������õ�big5�ַ��������⣬����������������������䲼���������ͨ���ּ���big5�ַ�������ʹ�ú��ֵ����պ��ȵأ�ͬһ�����ֶ��в�ͬ�������ʾ��
���ּ�������Ϣ����У����һ���Ͷ����dz���Ĺ������������Щ�ַ����е�ÿ�����ֶ�����һ�α��룬�ǽ������������ҵ��Ǽ�ʹ�������ڵ��ַ�����ͬ������ijһ�̶ֹ��ı��뷨��ͬ��״�ĺ���Ӧ�þ�����ͬ��������롣
��windows98��NT���Ժ��ϵͳƽ̨����ȫ֧��unicode��Unicode�ڻ���������ƽ���а����ĺ����ַ�����Ϊ27487����ԶԶ�������������ַ�������unicode�ڸ���Ӧ�������в�û�й㷺��Ӧ�ã����ԣ�ǰ�ڵĴ�����������һЩ�鷳����ˣ�������ϵͳ�ĵײ㣬���ֲ���unicode���룬�����뱾��ǰ�ڴ���ʱ������ѡȡgbk�ַ����µĿ������������б��롣
gbk�ַ����к���21003�����֣���gb2312��ȫ���ݣ��������ִ�½�ļ����ֺ�big5�ַ����µ�ȫ�������֣��dz�unicode���������ַ��������ڼ���ϵͳ�¹㷺ʹ�ã���ˣ�ʹ��unicode-gbk�����ģʽ������������ϵ�ж��ֶ�������ͬ��������ɺ��ֵ����롣
1�����ּ���Ӧ��������Ϣ��srm.dbf
�ֶκ� | �ֶ��� | �ֶ�˵�� |
1 | Hz | ���� |
2 | Srm | ������ |
3 | Zs1 | ��������Ϣ1 |
4 | Zs2 | ��������Ϣ2 |
5 | Zs3 | ��������Ϣ3 |
6 | Zs4 | ��������Ϣ4 |
7 | Rc | �ݴ������Ա�� |
8 | Jm | �������Ա�� |
2��������Ϣ��hz.dbf
�ֶκ� | �ֶ��� | �ֶ�˵�� |
1 | Hz | ���� |
2 | Bh | ���ֱʻ��� |
3 | Jg | ���ֽṹ��Ϣ |
4 | Pri | ����Ƶ����Ϣ |
5 | Ab | �����ּ��ϱ�� |
6 | Jf | ��� |
7 | Gb0 | Gb2312һ���ֱ�� |
8 | Gb | Gb2312��� |
9 | Gbkj | Gbk������ |
10 | Gbkf | Gbk������ |
11 | Unicode | �ú��ֵ�unicode���� |
12 | Gbk_ex | �Ƿ�Ϊgbk������ |
��
3��������ݵĻ��
��������Ϣ���ͺ�����Ϣ���У��в�����Ϣ�DZȽ�����õġ��纺���Ƿ�����gb2312���ϣ����ֽṹ��Ϣ�����ֱʻ�������Ϣ������һ������Ϣû���ֳ����ϣ���Ҫͨ��ͳ�ƻ�������
1�����ֱʻ������ṹ��Ϣ�Ļ�ȡ
���ֱʻ������ɺ����ֵ�����Ȼ�����˹����롣���ֽṹ��ϢҲ�ɸ����ֵ����ʾ���˹�ȷ�������롣
2�����������ַ����ı궨
����gb2312��gbk���Ӽ���������ȫ���ݣ��������뷶Χ�dz����ԣ�gb2312�����뷶Χ�ǣ�B0A1-FEFE,GB2312һ���ֵ����뷶Χ�ǣ�B0A1�D7FE����unicode�Ļ�ȡ��ֻ����windows2000ϵͳ�����½�hz.dbf�е�hz��һ�з��ڼ��±��У�Ȼ������unicode���룬��hz.dbf��д���Ӧ��unicode�ֶμ��ɡ�Unicode��������cjk unified ideograph�еĺ������뷶Χ��4e00-9fa5������20902�����֣������˷�Χ�Ĺ�101�����ֽ�gbk_ex.�궨Ϊ1��
3����������Ϣ�Ļ��
��gbk��21003�����ֽ��б���Ĺ�����Ҫ�൱ǿ�Ⱥ;��ȣ���Ȼ�������������Ϻ��ֱ���ģ�������������ṩһ���������㡢�˹�У�����Զ�������ϵı������һ�п���ʹ����������Կ��ɵĻ�������ɴ�����Ƿdz���Ҫ�ġ������DZ��뼰У�Գ���������棺
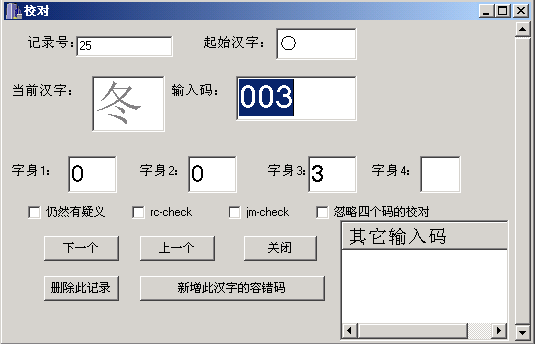
�˳������Ҫ��������:
��1���Ժ��ֽ��������롢������������Ϣ���ݴ���Ϣ�ı궨��У�ԡ�
��2������ʱ��ʾ�˺��ֵ����������롣
��3�������庺�������
��4���Զ������������������������Ϣ�Ƿ���ԡ�
��5��������ǰ���ֵ��ݴ������롣
4������Ƶ�ȵĻ��
���ֵ�Ƶ���Ǻ��ֵ�һ���dz���Ҫ�����ԡ����漰�����뺺�ֵij��ִ����뺺�ֵ�ȷ���ȡ������ֵ�Ƶ���ֲ���һ�ɲ���ģ����Ǹ��ݲ�ͬ��Ӧ������̬�����仯�ġ�
��ˣ���Ҫ��������Ϊÿһ�����ֻ�ȡһ���ȽϺ������۵ij�ʼƵ�ȡ�Ȼ���ݾ�������뻷�����ֹ���̬�ص���Ƶ�ȡ�ͨ������ͨ���Դ��������Ͻ���ͳ�Ʒ���������ÿ�����ֵ�ʹ�ô�����ͳ�ƺ��ֵij�ʼƵ�ȡ����Ա�дͳ�Ƴ���������ִ���������棬���Ҷ�Ӧ���ֵij��ִ��������㺺�ֵij�ʼƵ�ȡ�
���ڶ�̬��Ƶ���ұ�����Ϊ������һЩ���룬�����������ʱȽϵͣ�������ͨ������һ�������ǵ�����ϵͳ������Ч�ʣ����Բ��ؿ�������ܣ�������ƴ�����룬���������ʷdz�����ʹ����ϵͳ��һ����ѧϰ���Ե�Ƶ�Ĺ����Ƿdz���Ҫ�ġ�
5�����ּı궨
�����뷱���ֵķֱ�����Ҳû�кܺõı�����Ȼû�н��ޣ������ڼ����ֵIJ������ǶԲ��ַ����ֽ��мĽ�����������ǿ����������϶�������gb2312������Ϊ�Ǽ�����(gbkj=1)��������big5���ж�Ӧ���εĺ�������Ϊ�Ƿ�����(gbkf=1)����������Щ���ּ��Ƿ����֣����Ǽ����֡���Ȼ�����в��ֺ���δ���궨������Щ�ѱ��궨Ϊ�����δ���궨Ϊ������֣�Ҳ�����Ǽ����֣�������Щδ���궨���֣���ȿ����Ǽ����֣��ֿ����Ƿ����֡����Dz��õķ����Ƕ���Щ���֣�Ҳ����gb2312������word�����м�ת�������ת��������������ԭ��һ����ԭ�ּ�Ϊ�����֣�����Ϊ�����֡�
��
�ġ������뱾���ݿ���������Ϣ��ȡ
1�������뱾���ݿ�Ľṹ
��
��� | �ֶ��� | �ֶ�˵�� |
1 | Srm | ���������� |
2 | Hz | ���� |
3 | Pri | Ƶ�� |
4 | Gbkj | �Ƿ�Ϊ����� |
5 | gbkf | �Ƿ�Ϊ����� |
6 | Jm | �Ƿ�Ϊ���� |
7 | Rc | �Ƿ�Ϊ�ݴ��� |
2�������뱾��������
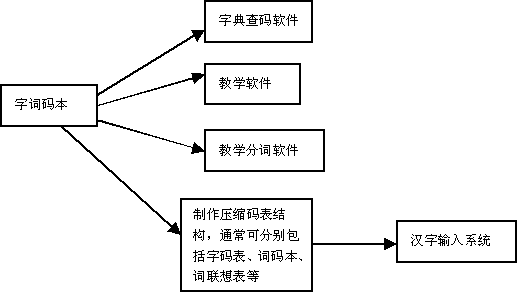
Ϊ�˷���Դ���Ĺ���������ɴ����Զ�����Ļ����ϣ�������ɴ���ij������롢ɾ�������鵼�������Ա궨�ȹ��ܡ��ݴˣ����Ա���һ�������뱾����������������Ϲ��ܡ�
1��������ռ�������
2��Ƶ�ȵĻ��
3���ı궨
4���ݴ���Ϣ�ı궨������Ļ�ȡ
��
�塢�ִ�ѹ���뱾����
1��ѹ���뱾����ṹ
�뱾���ֳ��������֣�
1������������(.idx�ļ�)��Ҫ������ʶ��Ϣ��������Ϣ��������������������������������������������������������������������������������������������ȡ����ļ���פ�ڴ档
<�����ļ�>����=<��ʶ��Ϣ><������Ϣ><������><������Ϣ>����=<����������><����������><����������������><���뱾����><���뱾����>�����������>
<������>����=<��������><��������> <������������>
<��������>����=<��������>[<��������>]
<��������>����=<��������>[<��������>]
<����������������>����=<��������>[<��������>]
<��������>����=<��Ӧ�������>
2��������֣�.mb�ļ�����Ҫ���������ֱ�������ʱ��������ֱ�������ʱ������������������������ȡ��ɸ�����Ҫ�ֱֵ����ڴ档���м���ͷ��������ṹ��ͬ��
<���뱾>����=<�������ֱ���>[<�������ֱ���>]
<���뱾>����=<������ʱ���>[<������ʱ���>]
<�������뱾>����=<����ʱ���>[<����ʱ���>]
<�������ֱ���>����=<3���ֽڵ��������BCD��>+<������ͬ�������������>+<���1>
<������ͬ����������������=<����>+<���2>
<���2>����=<��������1><ȫ��Ƶ�� ><����Ƶ��><����Ƶ��><����Ƶ��>
<���1>����=0xffff
<������ʱ���>����=<3���ֽڵ��������BCD��>+<������ͬ������Ĵ�����>+<���1>
<������ͬ������Ĵ��������=<����>+<��ǣ�>
<��ǣ�>����=<��������1><0xff><Ƶ������ ><��������1>
<����ʱ���>����=<ȥ�������е�һ�����ֵ����к���>+0xffff
����ѹ�����������ԭ��
ѹ�������������������������������������еĹؼ�������������������
���ȣ�������֮���Դ��ڵ������ǣ�������ϵͳ���Ӵ���뱾��������Ѱ��Ӧ������ĺ���ʱ�ܼӿ��ٶȡ����ԣ����ǵ����Ŀ���ǶԾ��й��Ե�һЩ���ֻ����ͳ����������е��ֽ��������ڶ�Ӧ������о��й��Եĺ��ֻ���汻��֯���ڽ��ĵط���
�������������뷨����������Ϊ�����ֱ���������������������ͬ������ĺ��ֶ�������һ�𡣶�ÿ��������ֱ���������ǰ��λ��ͬ�����������ֱ��е��ֽ������ڴ���λ�������У���һλ���ο�ȡֵ��0-9�����ڶ�λ���ο�ȡ���ո�0-9�� ����λ����Ҳ��ȡ���ո�0-9������������������Ϊ10*11*11��ÿһ�����趨Ϊ2�ֽڡ�����ǰ��λΪ��000���ĺ������ֱ��й���100�ֽڡ���Ӧ������������Ӧ�ڣ�0*11*11+1*10+1*10��λ����2�ֽڴ��100��
�����������ԭ���ɲ��������������Ƶķ�����
������������ʹ�����в��ԣ�������а��մ������ֵ�unicode������������Ҫ��Ŵ����֡�ÿ��������ֱ�����˱����Ӧ�����ֿ�ʼ�����д����ڴ�������е��ֽ�����unicode ���뷶ΧΪ4e00-9fa5������������ij���Ϊ20902�����е�һ������ݼ�Ϊunicode�еĵ�һ�����֡�һ����ʼ�����д����������뱾�е��ֽ�����
��